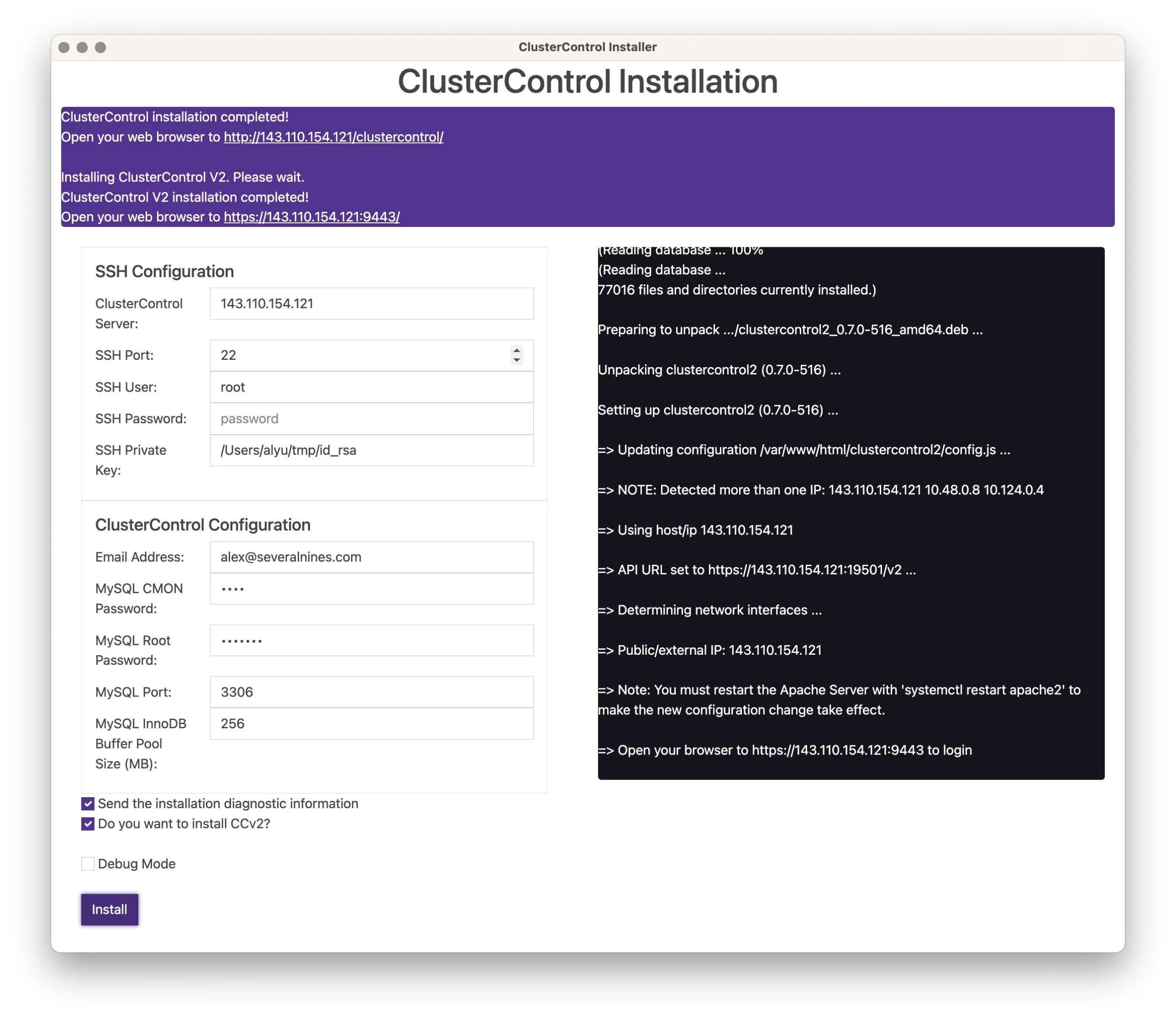
Step 1 - Make sure the replication configuration is setup correctly.
Step 2 – Install repmgr on primary and standby servers.
Make sure we install the same version of repmgr which is of our postgreSQL version. Since I am running postgreSQL version 13, I will be installing repmgr-13.
Note - We have to install it as a root user.
On Primary Server -
#yum -y install repmgr13*
On Standby Server -
#yum -y install repmgr13*
Step 3 – Configure postgresql.conf on Master and Standby nodes.
Since we have already configured replication, most of the parameters are already set. But just check on the below parameters and set whichever is missing.
shared_preload_libraries = 'repmgr'
max_wal_senders = 5
max_replication_slots = 10
wal_level = replica
hot_standby = on
archive_mode = on
archive_command = 'cp %p /home/postgres/arch_dir/% - We can have the different archive locations.
Listen_address=’*’
Step 4 – Create a replication manager user as repmgr.
Psql$ create user repmgr;
Psql$ create database repmgr owner repmgr;
Psql$alter user repmgr with superuser;
Step 5 – Create repmgr.conf on Primary node.Now we have to create repmgr.conf on Primary node. We can create it on any location but I have created under data directory only. My data directory is -
Create repmgr.conf with below parameters -
[postgres@Master master]$ cat repmgr.conf
cluster='failovertesting'
node_id=1
node_name=Master
conninfo='user=repmgr password=welcome host=192.168.204.133 dbname=repmgr port=5448 connect_timeout=2'
data_directory='/home/postgres/master/'
failover=automatic
promote_command='/usr/pgsql-13/bin/repmgr standby promote -f /home/postgres/master/repmgr.conf --log-to-file'
follow_command='/usr/pgsql-13/bin/repmgr standby follow -f /home/postgres/master/repmgr.conf --log-to-file --upstream-node-id=%n'
Parameter understanding –
failover='automatic'
The failover parameter is one of the mandatory parameters for the repmgr daemon. This parameter tells the daemon if it should initiate an automatic failover when a failover situation is detected. It can have either of two values: “manual” or “automatic”. We will set this to automatic in each node.
promote_command
promote_command= '/usr/pgsql-13/bin/repmgr standby promote -f /home/postgres/master/repmgr.conf --log-to-file'
This is another mandatory parameter for the repmgr daemon. This parameter tells the repmgr daemon what command it should run to promote a standby. The value of this parameter will be typically the “repmgr standby promote” command, or the path to a shell script that calls the command. For our use case, we set this to the following in each node:
follow_command
follow_command= '/usr/pgsql-13/bin/repmgr standby follow -f /home/postgres/master/repmgr.conf --log-to-file --upstream-node-id=%n'
This is the third mandatory parameter for the repmgr daemon. This parameter tells a standby node to follow the new primary. The repmgr daemon replaces the %n placeholder with the node ID of the new primary at run time.
priority
The priority parameter adds weight to a node’s eligibility to become a primary. Setting this parameter to a higher value gives a node greater eligibility to become the primary node. Also, setting this value to zero for a node will ensure the node is never promoted as primary.
Suppose we have two standbys: replica1 and replica2 and we want to promote replica2 as the new primary when master node goes offline, and replica2 to follow replica1 as its new primary. We set the parameter to the following values in the two standby nodes:
Node Name Parameter Setting
replica1 priority=60
replica2 priority=40
monitor_interval_secs
This parameter tells the repmgr daemon how often (default is seconds) it should check the availability of the upstream node. In our case, there is only one upstream node i.e the master node. The default value is 2 seconds, but we will explicitly set this anyhow in each node like below
monitor_interval_secs=2
connection_check_type
This parameter dictates the protocol repmgr daemon will use to reach out to the upstream node. This parameter can take three values:
ping: repmgr uses the PQPing() method.
connection: repmgr tries to create a new connection to the upstream node
query: repmgr tries to run a SQL query on the upstream node using the existing connection
Again, we will set this parameter to the default value of ping in each node:
connection_check_type='ping'
reconnect_attempts and reconnect_interval
When the primary becomes unavailable, the repmgr daemon in the standby nodes will try to reconnect to the primary for reconnect_attempts times. The default value for this parameter is 6. Between each reconnect attempt, it will wait for reconnect_interval seconds, which has a default value of 10.
For demonstration purposes, we will use a short interval and fewer reconnect attempts. We set this parameter in every node:
reconnect_attempts=4
reconnect_interval=8
primary_visibility_consensus
When the primary becomes unavailable in a multi-node cluster, the standbys can consult each other to build a quorum about a failover. This is done by asking each standby about the time it last saw the primary. If a node’s last communication was very recent and later than the time the local node saw the primary, the local node assumes the primary is still available, and does not go ahead with a failover decision.
To enable this consensus model, the primary_visibility_consensus parameter needs to be set to “true” in each node – including the witness:
primary_visibility_consensus=true
standby_disconnect_on_failover
When the standby_disconnect_on_failover parameter is set to “true” in a standby node, the repmgr daemon will ensure its WAL receiver is disconnected from the primary and not receiving any WAL segments. It will also wait for the WAL receivers of other standby nodes to stop before making a failover decision. This parameter should be set to the same value in each node. We are setting this to “true”.
standby_disconnect_on_failover=true
Setting this parameter to true means every standby node has stopped receiving data from the primary as the failover happens. The process will have a delay of 5 seconds plus the time it takes the WAL receiver to stop before a failover decision is made. By default, the repmgr daemon will wait for 30 seconds to confirm all sibling nodes have stopped receiving WAL segments before the failover happens.
Step 6 – Register Primary database cluster in the repmgr configuration
Since we have created the repmgr.conf file with the minimum required parameters. Now we have to register our primary database cluster in repmgr configuration.
[postgres@Master master]$ /usr/pgsql-13/bin/repmgr -f /home/postgres/master/repmgr.conf primary register
We can see primary node is registered successfully using below command –
[postgres@Master master]$ /usr/pgsql-13/bin/repmgr -f /home/postgres/master/repmgr.conf cluster show
Step 7 – Create repmgr.conf file on standby node.
We can create it in any location but I have created in the data directory only. My data directory is –
[postgres@Replica1 replica1]$ cat repmgr.conf
cluster='failovertesting'
node_id=2
node_name=Replica1
conninfo='host=192.168.204.134 user=repmgr password=welcome dbname=repmgr port=5448 connect_timeout=2'
data_directory='/home/postgres/replica1/'
failover=automatic
promote_command='/usr/pgsql-13/bin/repmgr standby promote -f /home/postgres/replica1/repmgr.conf --log-to-file'
follow_command='/usr/pgsql-13/bin/repmgr standby follow -f /home/postgres/replica1/repmgr.conf --log-to-file --upstream-node-id=%n'
Step 8 – Register Standby Database ClusterNow we have to register our standby database cluster in the repmgr configuration.
[postgres@Replica1 replica1]$ /usr/pgsql-13/bin/repmgr -f /home/postgres/replica1/repmgr.conf standby register
Getting below error –
Then I had to force register it like below –
[postgres@Replica1 replica1]$ /usr/pgsql-13/bin/repmgr -f /home/postgres/replica1/repmgr.conf standby register –force
But when I was showing cluster status on primary it was giving below warning –
[postgres@Master ~]$ /usr/pgsql-13/bin/repmgr -f /home/postgres/master/repmgr.conf cluster show
So I had to run below command on standby database.
[postgres@Replica1 ~]$ /usr/pgsql-13/bin/repmgr -f /home/postgres/replica1/repmgr.conf standby follow
After than when I checked the cluster status on primary it is running without any error –
I checked both the nodes and it is running fine –
/usr/pgsql-13/bin/repmgr -f /home/postgres/master/repmgr.conf node check
$/usr/pgsql-13/bin/repmgr –f /home/postgres/master/repmgr.conf cluster crosscheck
Step 9 – Start repmgrd process on master and standby
[postgres@Master ~]$ /usr/pgsql-13/bin/repmgrd -f /home/postgres/master/repmgr.conf
[postgres@Replica1 ~]$ /usr/pgsql-13/bin/repmgrd -f /home/postgres/replica1/repmgr.conf
We can see the series of events using cluster events commands –
When it starts monitoring then we will see the below details –
Repmgr Command Options –
====================The End=====
 Salah satu komponen dari Oracle Database adalah “datafile”. Pengertian sederhana dari datafile adalah kumpulan berkas tempat menyimpan semua database object. Contoh database object antara lain adalah
Salah satu komponen dari Oracle Database adalah “datafile”. Pengertian sederhana dari datafile adalah kumpulan berkas tempat menyimpan semua database object. Contoh database object antara lain adalah