Membandingkan operator Kubernetes untuk PostgreSQL

Klien kami cenderung bertanya kepada kami: "Dapatkah kami memiliki alternatif yang lebih murah untuk Amazon RDS?" atau "Bukankah akan luar biasa jika memiliki sesuatu seperti RDS, tidak hanya di AWS...". Nah, untuk memenuhi kebutuhan mereka dan menerapkan solusi terkelola seperti RDS di Kubernetes, kami melihat status terkini operator PostgreSQL yang paling populer: Stolon, Crunchy Data, Zalando, KubeDB, StackGres. Kami membandingkannya dan membuat pilihan kami sendiri.
Namun sebelum menganalisis apa yang kita miliki di dunia operator K8s untuk PgSQL, mari kita tentukan persyaratan umum untuk potensi penggantian Amazon RDS…
PEMBARUAN (Oktober 22): Harap perhatikan bahwa ada versi terbaru artikel ini , di mana kami memeriksa solusi lain (CNPG) dan memberikan perbandingan terkini dengan semua operator yang disebutkan di sini.
Apa itu RDS?
Dalam pengalaman kami, ketika orang merujuk pada “RDS”, mereka sering kali mengacu pada layanan DBMS terkelola yang:
- mudah untuk diatur;
- mendukung snapshot dan dapat menggunakannya untuk pemulihan (sebaiknya dengan dukungan PITR );
- memungkinkan Anda membuat topologi master/slave;
- memiliki daftar ekstensi yang luas;
- memungkinkan Anda melakukan audit dan mengelola pengguna/akses basis data.
Secara umum, pendekatan untuk melakukan penggantian RDS dapat sangat bervariasi, tetapi cara seperti Ansible tidak cocok untuk kita. Dalam ekosistem Kubernetes, operator dianggap sebagai metode yang diterima secara umum untuk menyelesaikan tugas-tugas tersebut.
Dengan menghadirkan RDS ke lanskap Kubernetes, kami memperluas fitur-fitur penting yang disebutkan di atas dengan rekomendasi (persyaratan?..) berikut untuk operator:
- kemampuan untuk menyebarkannya dari Git dan melalui Sumber Daya Kustom ;
- dukungan untuk fitur anti-afinitas pod;
- kemampuan untuk menentukan afinitas node atau aturan pemilih node;
- dukungan untuk toleransi polong;
- cukup fleksibel untuk disesuaikan secara halus;
- teknologi terkenal dan bahkan perintah yang digunakan.
Tanpa membahas secara rinci poin-poin ini (Anda dipersilakan untuk mengajukan pertanyaan di kolom komentar di bawah), kami ingin mencatat bahwa parameter ini memungkinkan pengguna untuk menentukan spesialisasi node kluster secara lebih tepat untuk menjalankan aplikasi tertentu di dalamnya. Dengan cara ini, kami dapat mencapai keseimbangan terbaik antara kinerja dan biaya.
Ada beberapa operator PostgreSQL populer untuk Kubernetes:
- Stolon;
- Operator PostgreSQL Data Crunchy;
- Operator Zalando Postgres;
- KubeDB;
- StackGres adalah aplikasi yang memungkinkan Anda untuk membuat profil pengguna yang unik dan menarik.
Mari kita cermati lebih dekat.
1. Stolon
![]()
Stolon oleh Sorint.lab memiliki sejarah yang kaya: rilis publik pertamanya terjadi pada November 2015(!), dan repositori GitHub-nya memiliki 3.100+ bintang dan 40+ kontributor.
Proyek ini adalah contoh terbaik dari arsitektur yang dirancang dengan baik:
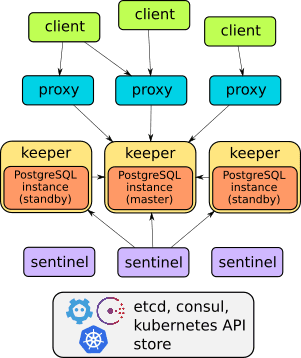
Anda dapat mempelajari lebih lanjut tentang operator dalam dokumentasi proyek . Secara keseluruhan, operator ini memiliki semua fitur yang disebutkan di atas, seperti fungsi failover, proxy untuk akses klien yang transparan, dan pencadangan. Selain itu, proxy menyediakan akses melalui satu titik akhir (tidak seperti solusi lain yang dibahas di bawah ini – mereka memiliki dua layanan untuk mengakses basis data).
Sayangnya, Stolon tidak mendukung Custom Resources , yang mempersulit pembuatan instans DBMS di kluster Kubernetes. stolonctlAlat tersebut mengontrol kluster Stolon. Operator disebarkan melalui bagan Helm, dan parameter pengguna didefinisikan dalam ConfigMap.
Di satu sisi, ternyata Stolon bukanlah operator dalam arti sebenarnya (karena tidak menggunakan CRD). Di sisi lain, ini adalah sistem fleksibel yang memungkinkan Anda mengonfigurasi sumber daya Kubernetes sesuai keinginan Anda.
Singkatnya, kami merasa ide membuat bagan Helm terpisah untuk setiap DB kurang optimal. Itulah sebabnya kami mulai mencari alternatif.
2. Operator PostgreSQL Data Crunchy
![]()
Operator oleh Crunchy Data tampaknya menjadi alternatif yang bagus. Versi pertamanya dirilis pada Maret 2017. Saat ini, repositori Crunchy Data memiliki 1500+ bintang dan 60+ kontributor. Rilis terbaru (v4.6.0 dari Januari 21) telah diuji untuk bekerja dengan Kubernetes 1.17—1.20, OpenShift 3.11 & 4.4+, GKE, EKS, AKS, dan VMware Enterprise PKS 1.3+.
Arsitektur Operator PostgreSQL Crunchy Data juga memenuhi persyaratan kami:

Alat yang disebut pgo mengelola operator dan menghasilkan Sumber Daya Kustom Kubernetes. Sebagai calon pengguna, kami senang dengan fitur operator, seperti:
- dukungan untuk CRD;
- manajemen pengguna yang nyaman (melalui CRD);
- integrasi dengan komponen lain dari Crunchy Data Container Suite – kumpulan khusus gambar kontainer PostgreSQL dan alat yang berguna (termasuk pgBackRest , pgAudit , ekstensi contrib, dan sebagainya).
Namun, upaya kami dalam menggunakannya menemui beberapa masalah:
- Ternyata, Anda tidak dapat menggunakan toleransi di Crunchy Data, hanya
nodeSelectortoleransi yang disediakan. (PEMBARUAN: Fitur ini baru saja diterapkan, dalam v4.6.0 yang dirilis pada Januari '21, namun evaluasi kami telah dilakukan sebelumnya, pada tahun 2020.) - Pod yang kami buat merupakan bagian dari Deployment (meskipun kami telah menerapkan aplikasi berstatus). Seperti yang Anda ketahui, tidak seperti StatefulSet, Deployment tidak dapat membuat volume.
Kelemahan kedua ini telah menyebabkan beberapa hasil yang aneh. Misalnya, kami dapat meluncurkan tiga replika menggunakan penyimpanan lokal yang sama . Sementara itu, Crunchy Data menyatakan bahwa ketiga replika tersebut berjalan normal (meskipun itu jauh dari kenyataan).
Fitur penting lain dari operator ini adalah dukungan bawaannya untuk berbagai sistem tambahan. Misalnya, Anda dapat dengan mudah memasang pgAdmin dan PgBouncer, dan dokumentasinya menjelaskan pemasangan pgMonitor, Grafana, dan Prometheus yang telah dikonfigurasi sebelumnya untuk mengumpulkan & memvisualisasikan metrik langsung dari tempatnya.
Namun, kami merasa perlu mencari solusi lain karena pemilihan sumber daya Kubernetes yang dihasilkan membingungkan kami.
3. Operator Postgres Zalando
![]()
Kami memiliki sejarah panjang dalam penggunaan produk Zalando: kami telah bekerja dengan Zalenium dan mencoba Patroni , solusi PostgreSQL HA mereka yang populer. Mendengarkan Alexey Klyukin, salah satu penulis Postgres Operator , telah membuat kami menyukai desain proyek ini dan mempertimbangkan untuk menggunakannya.
Solusi ini lebih muda dari dua solusi pertama karena rilis pertamanya terjadi pada Agustus 2018 dan jumlah rilisnya relatif sedikit selama sejarahnya. Namun, proyek ini telah berkembang pesat dan mencapai popularitas Crunchy Data, sebagaimana dibuktikan oleh 1500+ bintang di GitHub dan lebih dari 90 kontributor.
Zalando Postgres Operator didasarkan pada solusi yang telah terbukti “di balik layar”, seperti:
Berikut arsitekturnya:

Operator dikelola melalui Custom Resources. Operator ini dapat secara otomatis membuat StatefulSet dari kontainer, dan Anda dapat menyesuaikannya nanti dengan melampirkan berbagai kontainer sidecar ke pod. Dengan demikian, operator Zalando cukup sebanding dengan operator Crunchy Data.
Akhirnya, kami memilih operator Zalando sebagai pilihan kami . Kami akan menjelaskan kemampuannya secara lengkap dan menunjukkan cara menggunakannya di artikel berikutnya. ( UPDATE : Artikel ini sekarang tersedia di sini !) Dan sekarang saatnya untuk dua operator lagi, StackGres & KubeDB, dan tabel perbandingan fitur.
4. KubeDB
![]()
Tim AppsCode telah mengembangkan operator KubeDB sejak 2017 dan dikenal luas di komunitas Kubernetes. Sebenarnya, KubeDB diposisikan sebagai platform yang lebih “berskala luas” untuk menjalankan berbagai layanan stateful di Kubernetes. Platform ini mendukung:
- Bahasa pemrograman PostgreSQL;
- Pencarian Elastis;
- MySQL;
- Bahasa Pemrograman MongoDB;
- Merah;
- Memcache.
Namun, dalam artikel ini, kami akan mempertimbangkan PostgreSQL saja.
KubeDB mengimplementasikan pendekatan menarik yang melibatkan beberapa CRD yang berisi berbagai pengaturan:
- Sumber daya tersebut
postgresversions.catalog.kubedb.commenyimpan citra basis data dan alat tambahan; codesnapshots.kubedb.com— parameter pemulihan untuk cadangan;postgreses.kubedb.com — sumber daya pusat yang menggunakan semua sumber daya “dasar” dan memulai klaster PostgreSQL.
KubeDB tidak terlalu dapat disesuaikan (tidak seperti operator Zalando), tetapi Anda dapat mengelola konfigurasi PostgreSQL melalui objek ConfigMap dan menggunakan gambar kustom Anda untuk Postgres .
Fitur eksotisnya adalah dormantdatabases.kubedb.comsumber daya. Sumber daya ini melindungi dari tindakan yang tidak diinginkan/salah: semua basis data yang dihapus diarsipkan dan disalin ke sumber daya ini, sehingga Anda dapat memulihkannya jika/ketika diperlukan. Diagram berikut menunjukkan siklus hidup basis data di KubeDB:
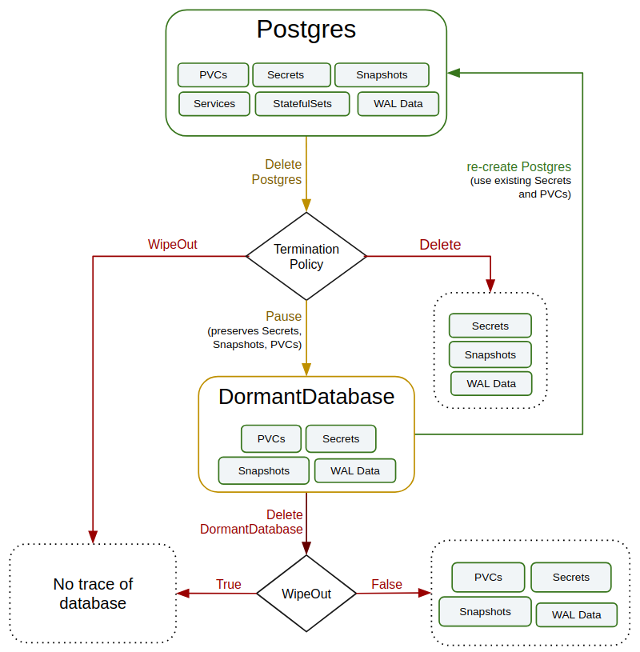
KubeDB menggunakan alat internal untuk mengelola kluster, bukan Patroni atau Repmgr yang sudah dikenal luas. Sementara itu, PgBouncer digunakan untuk penggabungan koneksi. Alat ini juga dibuat oleh CRD ( pgbouncers.kubedb.com). Berikut ini adalah plugin kubectl : dengan plugin ini, Anda dapat mengelola basis data menggunakan alat CLI yang sudah dikenal luas, dan ini merupakan keuntungan besar dibandingkan Stolon atau Crunchy Data.
KubeDB terintegrasi dengan solusi AppsCode lainnya (mirip dengan Crunchy Data). Jika Anda sangat bergantung pada perangkat vendor ini, maka KubeDB adalah pilihan yang tepat dan sangat baik.
Terakhir, saya ingin menarik perhatian Anda pada fakta bahwa operator ini didokumentasikan dengan sangat baik, dan semua dokumentasi disimpan dalam repositori GitHub yang terpisah . Ada contoh penggunaan terperinci, termasuk contoh konfigurasi CRD yang menyeluruh.
Namun, KubeDB juga memiliki kekurangan. Banyak fitur — termasuk pencadangan, penggabungan koneksi, snapshot, database dorman — hanya tersedia dalam versi perusahaan . Untuk menggunakannya, Anda perlu membeli langganan dari AppsCode. Mungkin itu sebabnya repo GitHub-nya kurang populer di komunitas, dengan kurang dari 400 bintang dan 10 kontributor.
Selain itu, versi PostgreSQL terbaru yang didukung secara default adalah 11.x. Apakah poin-poin ini meniadakan arsitektur KubeDB yang elegan, terserah Anda untuk memutuskan.
5. Tumpukan Gres
![]()
Operator StackGres merupakan solusi termuda dalam ulasan kami, karena baru saja dimulai, pada bulan Mei 2019. Karena repo utamanya dihosting di GitLab , tidak ada cara untuk membandingkan nomor bintang dengan GitHub. Operator ini menggunakan teknologi yang terkenal dan terbukti: Patroni, PgBouncer, WAL-G, dan Envoy.
Berikut cara kerja StackGres secara umum:

Anda juga dapat memasang bersama operator:
- panel web (seperti milik Zalando);
- sistem pengumpulan log;
- sistem pemantauan yang mirip dengan Crunchy Data;
- sistem agregasi cadangan berbasis MinIO (Anda juga dapat menghubungkan penyimpanan eksternal).
Operator ini menggunakan pendekatan yang serupa dengan KubeDB: menyediakan beberapa sumber daya untuk mendefinisikan komponen kluster, membuat file konfigurasi, dan mengatur sumber daya.
Berikut spesifikasi CRD:
sgbackupconfigs.stackgres.io,sgpgconfigs.stackgres.io,sgpoolconfigs.stackgres.iomemungkinkan Anda menentukan konfigurasi khusus;sginstanceprofiles.stackgres.iomenentukan ukuran instans Postgres (yang akan digunakan sebagai batas/permintaan untuk kontainer PostgreSQL/Patroni). Tidak ada batas untuk kontainer lainnya;sgclusters.stackgres.io— jika ada konfigurasi untuk database, kumpulan koneksi, dan cadangan, Anda dapat membuat kluster StackGres PostgreSQL menggunakan CRD ini;sgbackups.stackgres.ioadalah sumber daya yang mirip dengan snapshot KubeDB, sehingga memungkinkan Anda membuat dan mengelola cadangan dari dalam kluster K8s.
Namun, operator tidak mendukung pembuatan citra kustom atau beberapa kontainer sidecar untuk server basis data. Pod Postgres berisi lima kontainer:
Dari semua ini, kita dapat menonaktifkan pengekspor metrik, pengumpul koneksi, dan kontainer dengan alat tambahan ( psql, pg_dump, dll.). Saat memulai klaster basis data, StackGres memungkinkan Anda menggunakan skrip SQL untuk menginisialisasi basis data atau membuat pengguna. Namun, sayangnya, hanya itu yang dapat Anda lakukan. Hal ini sangat membatasi kemampuan kustomisasi dibandingkan dengan, misalnya, operator Zalando. Operator Zalando memungkinkan Anda untuk memasang sidecar yang berisi Envoy, PgBouncer, atau kontainer tambahan lainnya (di bawah ini, kami akan memeriksa contoh yang baik dari bundel tersebut).
Singkatnya, operator ini cocok bagi mereka yang ingin "hanya mengelola" database PostgreSQL dalam kluster Kubernetes. StackGres merupakan pilihan yang sangat baik jika Anda memerlukan alat dengan dokumentasi yang jelas dan mudah dipahami yang mencakup semua aspek pekerjaan operator dan tidak perlu membuat konfigurasi yang rumit dari kontainer dan database.
Perbandingan
Kami tahu bahwa pembaca/rekan kerja kami menyukai tabel ringkasan, jadi kami telah menyusunnya. Tabel ini membandingkan berbagai operator Postgres untuk Kubernetes.
Petunjuk: setelah mempertimbangkan dua kandidat tambahan, kami masih berpikir bahwa operator Zalando adalah produk yang optimal untuk kasus penggunaan kami. Operator ini memungkinkan kami menerapkan solusi yang sangat fleksibel dan memiliki potensi besar untuk penyesuaian.
Bagian pertama tabel mengkaji fitur-fitur penting yang dibutuhkan untuk bekerja dengan basis data, bagian kedua membandingkan fungsi-fungsi yang lebih spesifik (menurut keyakinan kami tentang kemudahan penggunaan operator di Kubernetes).
PEMBARUAN (Oktober 22): Harap perhatikan bagian kedua artikel ini dengan tabel perbandingan yang diperbarui dan solusi lain (CNPG) yang ditambahkan.
Perlu juga dicatat bahwa kami mendasarkan kriteria kami untuk tabel ringkasan pada contoh dari dokumentasi KubeDB.
| stolon | Data Renyah | Zalando | KubeDB | TumpukanGres | |
| Versi terbaru (pada saat penulisan) | 0.16.0 | 4.5.0 | 1.6.0 | tanggal26 Januari 2021 | 0.9.4 |
| Versi PostgreSQL yang didukung | 9.4—9.6, 10, 11, 12 | 9.5, 9.6, 10, 11, 12 | 9.6, 10, 11, 12, 13 | 9.6, 10, 11 | 11, 12 |
| Fitur umum | |||||
| klaster PgSQL | ✓ | ✓ | ✓ | ✓ | ✓ |
| Siaga panas dan hangat | ✓ | ✓ | ✓ | ✓ | ✓ |
| Replikasi sinkron | ✓ | ✓ | ✓ | ✓ | ✓ |
| Replikasi streaming | ✓ | ✓ | ✓ | ✓ | ✓ |
| Kegagalan otomatis | ✓ | ✓ | ✓ | ✓ | ✓ |
| Pengarsipan berkelanjutan | ✓ | ✓ | ✓ | ✓ | ✓ |
| Inisialisasi: menggunakan arsip WAL | ✓ | ✓ | ✓ | ✓ | ✓ |
| Pencadangan instan dan terjadwal | ✗ | ✓ | ✓ | ✓ | ✓ |
| Mengelola cadangan dengan cara asli Kubernetes | ✗ | ✗ | ✗ | ✓ | ✓ |
| Inisialisasi: menggunakan snapshot + skrip | ✓ | ✓ | ✓ | ✓ | ✓ |
| Fitur khusus | |||||
| Dukungan Prometheus bawaan | ✗ | ✓ | ✗ | ✓ | ✓ |
| Konfigurasi khusus | ✓ | ✓ | ✓ | ✓ | ✓ |
| Gambar Docker Kustom | ✓ | ✓ | ✓ | ✓ | ✗ |
| Utilitas CLI eksternal | ✓ | ✓ | ✗ | ✓* | ✗ |
| Konfigurasi berbasis CRD | ✗ | ✓ | ✓ | ✓ | ✓ |
| Pod Kustom | ✓ | ✗ | ✓ | ✓ | ✗ |
| Pemilih Node dan Afinitas Node | ✓ | ✓ | ✓ | ✓ | **✗** |
| Toleransi | ✓ | ✓ | ✓ | ✓ | **✗** |
| Pod anti-afinitas | ✓ | ✓ | ✓ | ✓ | ✓ |
* KubeDB memiliki plugin kubectl.
** Meskipun penyeleksi node diharapkan berfungsi dalam versi StackGres yang dievaluasi, kami belum menemukan fitur ini. Rilis v1.0 mendatang dari operator ini seharusnya memiliki dukungan afinitas dan toleransi node.
Kesimpulan
Mengelola PostgreSQL di Kubernetes bukanlah tugas yang mudah. Mungkin, saat ini, belum ada operator yang mampu memenuhi semua kebutuhan teknisi DevOps. Namun, ada beberapa alat yang cukup canggih dan matang di antara solusi yang ada, dan Anda dapat memilih salah satu yang paling sesuai dengan kebutuhan Anda.
Saat meninjau solusi yang paling populer, kami memilih Postgres Operator by Zalando. Ya, memang ada beberapa kesulitan, dan kami akan membahasnya di artikel berikutnya. Jika Anda memiliki pengalaman dengan solusi serupa, silakan bagikan di kolom komentar!
Tidak ada komentar:
Posting Komentar