Kubernetes Bare-metal, Bagian I: Talos di Hetzner
Diskusi di Hacker News
Saya telah menjalankan klaster Kubernetes pada gabungan mesin virtual dan bare metal dengan Hetzner selama sekitar satu tahun sekarang, dan meskipun pengaturannya telah melayani saya dengan baik, karena pada saat itu masih merupakan latihan yang sangat eksploratif, hal itu tidak terdokumentasi dengan baik.
Untuk memperbaiki hal ini, dan agar mendapat kesempatan bermain dengan beberapa alat yang belum saya ketahui saat itu, saya memutuskan untuk membangun kembali kluster dari awal dan mendokumentasikan prosesnya melalui postingan ini.
Saya punya sketsa kasar tentang produk akhir dalam pikiran saya, yang saya rencanakan untuk diwujudkan melalui langkah-langkah/posting berikut:
Bagian I: Talos di Hetzner Meliputi penyediaan server pertama, instalasi Talos Linux dan konfigurasi dan bootstrapping
Bagian II: Cilium CNI & Firewall Memilih CNI dan menerapkan kebijakan jaringan dan aturan firewall tanpa mengunci diri kita sendiri.
Bagian III: GitOps Terenkripsi dengan FluxCD Melacak sumber daya yang disebarkan dengan FluxCD, menggunakan SOPS untuk menyimpan rahasia enkripsi dalam repositori.
Bagian IV: Ingress, DNS, dan Sertifikat Menginstal pengontrol ingress (nginx), pengontrol DNS (external-dns), dan manajer sertifikat untuk mengotomatiskan perutean.
Bagian V: Scaling Out Satu node tidak membuat sebuah cluster! Waktu untuk menskalakan cluster hingga 3 node
Bagian VI: Penyimpanan Permanen dengan Rook Ceph Dengan 3 node dan 6 disk yang tersedia, kami akhirnya memenuhi syarat untuk menyimpan data jangka panjang, yang akan kami perlukan ke depannya.
Bagian VII: Registri Pribadi dengan Harbor Penyimpanan persisten memungkinkan kita menyimpan dan menyimpan gambar yang kita gunakan, jadi mari!
Bagian VIII: Mengontainerisasi Lingkungan Kerja Kita Kompilasi seluruh lingkungan kerja kita ke dalam satu citra tunggal agar pemutakhiran menjadi mudah.
Bagian IX: Memperbarui Penerapan Lama Mengotomatiskan tugas membosankan untuk memastikan semua bagan dan gambar helm Anda mutakhir.
Bagian X: Metrik dan Pemantauan dengan OpenObserve Menyiapkan OpenObserve untuk memantau dan mengukur kesehatan kluster kita, dan semua beban kerja yang berjalan di dalamnya.
Kode sumber lengkap untuk klaster langsung tersedia di @github/MathiasPius/kronform
Memilih Distribusi Kubernetes
Saya telah menerapkan kluster Kubernetes dalam berbagai cara selama bertahun-tahun, dengan segala macam kombinasi k8s|k3s|k0s menggunakan kubeadm| dengan cara yang sulit |dikelola (EKS & Exoscale) yang dikemas menggunakan Docker dan Packer milik Hashicorp dan diterapkan dengan Ansible atau Terraform, atau yang lebih baru Penyedia API Kluster milik syself untuk Hetzner .
Kesimpulan saya saat ini adalah jika Anda mampu membelinya, baik dari segi privasi/GDPR maupun dollarinos, maka cara yang tepat adalah dengan mengelolanya . Jika tidak mampu, maka Anda harus melakukan sedikit investigasi.
Semua alat yang berbeda yang telah saya coba tampak hebat di atas kertas, tetapi biasanya memiliki beberapa kekurangan atau peringatan yang mengganggu.
Bagi Packer dan Terraform, ini adalah manajemen status. Membangun citra mesin virtual statis untuk semua bidang kontrol dan node pekerja Anda terdengar hebat secara teori, tetapi Anda harus meletakkan citra tersebut di suatu tempat . Kluster Kubernetes juga bukan struktur idempoten murni, meskipun sebagian besar bercita-cita untuk menjadi demikian. Menangani bootstrapping kluster, penggabungan node, dll. di Terraform hampir mustahil, bukan karena Terraform adalah alat yang buruk, tetapi karena alat tersebut sangat jauh dari jangkauan yang seharusnya. Terraform adalah tentang status yang diinginkan, tetapi Anda tidak dapat "menginginkan" cara Anda untuk melakukan bootstrapping sistem terdistribusi kecuali seseorang telah menyembunyikan semua detail penting dari Anda di balik layanan terkelola.
Bahasa Indonesia: Untuk Cluster API dan penyedianya, masalahnya lebih merupakan masalah saya daripada masalah mereka. Ini adalah pengaturan yang sangat fleksibel, yang memungkinkannya bekerja di begitu banyak penyedia dan skenario, bahkan yang tidak berupaya menyediakan dukungan Kubernetes resmi apa pun seperti Hetzner, atau kluster Raspberry Pi desktop Anda sendiri. Semua aspek kluster itu sendiri dikelola melalui Kubernetes dan Definisi Sumber Daya Kustom, yang keren dengan sendirinya, tetapi jika Anda menggali lebih dalam tentang penyedia Hetzner, Anda akan menyadari bahwa itu adalah menara yang dibangun di atas bash . Semua ini seharusnya tidak mendiskualifikasi penggunaannya, tetapi pengalaman saya dengannya adalah salah satu kebingungan. Itu melakukan semua yang seharusnya, tetapi kadang-kadang sangat sulit untuk mengikuti mengapa ia melakukan apa yang dilakukannya, atau bagaimana. Seperti yang saya katakan, saya sangat terkesan dengan pekerjaan mereka dan Cluster API mungkin menjadi masa depan, jadi itu mungkin masalah saya.
Untuk k3s , k0s, dan semua distribusi Kubernetes minimal lainnya, masalahnya adalah keselarasan . Mereka mampu mencapai alur penyebaran dan pengaturan yang efisien dengan membuat banyak keputusan sulit untuk Anda, yang merupakan hal yang bagus selama nilai-nilai Anda selaras dengan nilai-nilai mereka, jika tidak, Anda harus berkompromi, meretas, atau berbalik arah.
Talos Linux tentu saja mengalami kutukan yang sama seperti k3s dan k0s, yang membuat pengambilan keputusan menjadi ekstrem dan bahkan memilih kernel untuk Anda. Namun untungnya, pilihan mereka selaras dengan kebutuhan dan nilai saya. Saya sangat menyukai filosofi distribusi berorientasi kontainer dan sebelumnya telah mencoba Flatcar Container Linux , tetapi setidaknya pada saat itu saya merasa sangat sulit untuk mulai bekerja pada server bare metal Hetzner, meskipun alasan pastinya tidak saya pahami saat ini.
Setelah membaca dokumentasi untuk Talos Linux, saya sangat menyukai pendekatan mereka terhadap konfigurasi node dan kluster. Pendekatan mereka sangat mirip dengan pendekatan Cluster API, tetapi dengan memiliki distribusi Linux yang mendasarinya dan tidak bergantung pada alat yang sudah ada seperti kubeadm untuk berinteraksi dengan kluster, mereka dapat menyederhanakan antarmuka yang diekspos ke administrator secara radikal, yang membuatnya setidaknya tampak seperti pengalaman yang sangat menyenangkan.
Berdasarkan perasaan yang sangat subjektif itu, pengalaman masa lalu saya, dan tentu saja anggapan bahwa rumput tetangga selalu lebih hijau, Talos Linux adalah pilihan saya untuk kluster ini.
Menginstal Talos pada Server Khusus
Panduan Memulai Cepat dan Panduan Memulai mereka dapat membantu Anda memulai dengan kluster berbasis Docker lokal, atau menginstalnya pada salah satu penyedia yang didukung, tetapi penerapannya ke server khusus Hetzner memerlukan beberapa langkah tambahan.
Kami tidak dapat menyediakan server khusus dengan ISO khusus untuk melakukan booting, tetapi kami dapat melakukan booting ke sistem penyelamatan Hetzner dan menulis ISO Talos langsung ke hard drive yang berarti bahwa saat berikutnya kami melakukan booting ulang server (dengan ketentuan tidak ada disk lain yang memiliki konfigurasi booting yang valid dan diutamakan), server kami akan melakukan booting ke instance Talos yang tidak dikonfigurasikan yang berjalan dalam mode Pemeliharaan. Ini adalah skrip yang saya gunakan untuk menginstal Talos v1.4.4 ke server khusus saya dari sistem penyelamatan Linux:
pesta# I'm intentionally picking a version that's behind by patch version so I
# can try out the upgrade procedure once it's up and running.
TALOS_VERSION="v1.4.4"
# Keep in mind that device paths might change between reboots so either
# double-check the device path, or use one of the udev paths instead.
TARGET_DISK="/dev/sda"
# Download the release asset designed for (bare) metal deployments.
wget -O /tmp/talos.tar.gz https://github.com/siderolabs/talos/releases/download/$TALOS_VERSION/metal-amd64.tar.gz
# Unpack the archive
tar -xvf /tmp/talos.tar.gz
# Write the raw disk image directly to the hard drive.
dd if=disk.raw of=$TARGET_DISK && sync
shutdown -r now
Setelah beberapa saat server akan kembali aktif, jadi mari kita lihat apakah berfungsi dengan menggunakan talosctlutilitas baris perintah untuk berinteraksi dengan API talos (yang mudah-mudahan aktif) di node tersebut:
pesta[mpd@ish]$ talosctl -n 159.69.60.182 disks --insecure
error getting disks: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing: dial tcp 159.69.60.182:50000: i/o timeout"
Aneh! Server tidak merespons pada titik akhir API Talos, sepertinya ada yang salah.
Mengaktifkan sistem penyelamatan Hetzner vKVM dan memaksa pengaturan ulang perangkat keras akan mem-boot server, dan saya dapat melihat antarmuka Talos. Bahkan sekarang ia menanggapi permintaan saya:
pesta[mpd@ish]$ talosctl -n 159.69.60.182 disks --insecure DEV MODEL TYPE MODALIAS SIZE BUS_PATH SYSTEM_DISK /dev/sda QEMU HARDDISK HDD scsi:t-0x00 2.0 TB .../0:0:0:0/ /dev/sdb QEMU HARDDISK HDD scsi:t-0x00 2.0 TB .../1:0:0:0/ /dev/sdc QEMU HARDDISK HDD scsi:t-0x00 256 GB .../2:0:0:0/ *
output dipotong agar sesuai
Saya pernah mengalami masalah yang dipecahkan secara ajaib oleh sistem vKVM Hetzner sebelumnya, jadi saya tidak yakin kita sudah keluar dari masalah. Jika kita dapat mem-boot sistem tanpa sistem vKVM, saya akan menganggapnya sebagai kebetulan acak dan melanjutkan konfigurasi.
Setelah pengaturan ulang perangkat keras lainnya (tanpa sistem penyelamatan), Talos masih menanggapi permintaan kami. Saya masih belum yakin penyebabnya, tetapi mari kita lanjutkan 1 .
Mengonfigurasi Talos
Untuk membangun kluster Kubernetes dari Talos, Anda harus mengonfigurasi Talos terlebih dahulu. Ini dilakukan dalam dua langkah, pertama dengan membuat yang talosconfigberisi kubeconfigdefinisi kumpulan titik akhir Talos dan kredensial untuk mengaksesnya. Dengan Kubernetes, Anda biasanya mengonfigurasi kluster terlebih dahulu lalu mengekstrak kubeconfig, tetapi dengan Talos, Anda membuat konfigurasi terlebih dahulu lalu mencetaknya pada masing-masing node.
Mengikuti panduan Memulai , pertama-tama kita harus memutuskan nama dan titik akhir kluster. Tujuan saya adalah menjalankan kluster ini murni pada perangkat keras, jadi saya tidak ingin menempatkan penyeimbang beban di depan kluster, meskipun konfigurasi khusus itu bekerja dengan baik bagi saya di masa lalu. Saya ingin sedekat mungkin dengan pengaturan DIY, sehingga berpotensi dapat dimigrasikan atau diperluas ke lokal di kemudian hari. Untuk alasan yang sama, dan karena tingginya biaya yang terkait dengannya, penggunaan vSwitch dan IP mengambang juga tidak mungkin.
Saya memilih menggunakan penyeimbangan beban DNS, karena saya tidak memperkirakan akan terjadi banyak pergantian pada node bidang kontrol/talos, ataupun beban yang berat.
Nama Cluster dan Titik Akhir
Mari kita mulai dengan mengekspor nama klaster dan titik akhir kita untuk referensi di masa mendatang. Saya telah memilih nama klaster "kronform" secara semi-arbitrer, dan akan menggunakannya sebagai subdomain dari salah satu domain saya yang sudah ada untuk mengaksesnya.
pesta[mpd@ish]$ export CLUSTER_NAME="kronform"
[mpd@ish]$ export API_ENDPOINT="https://api.kronform.pius.dev:6443"
DNS
Buat rekaman DNS yang menunjuk ke satu node kita, sehingga punya peluang untuk disebarkan saat kita membutuhkannya.

Saya telah mengonfigurasikan IPv4 dan IPv6 serta menetapkan waktu hidup yang rendah, jadi jika suatu node mati dan harus dihapus dari kluster di masa mendatang, alamatnya akan segera dihapus dari sebagian besar cache DNS.
Rahasia
Pertama-tama kita perlu membuat kumpulan rahasia yang berisi semua kunci sensitif yang digunakan untuk mendefinisikan klaster kita:
pesta[mpd@ish]$ talosctl gen secrets --output-file secrets.yaml
Kita perlu menyimpan berkas ini secara aman, tetapi tidak dapat mengirimkannya ke git hingga kita memiliki metode untuk mengenkripsinya.
konfigurasi talos
Hasilkan talosconfigberdasarkan nama kluster dan titik akhir yang ditentukan sebelumnya.
pesta[mpd@ish]$ talosctl gen config \
--with-secrets secrets.yaml \
--output-types talosconfig \
--output talosconfig \
$CLUSTER_NAME \
$API_ENDPOINT
Saya tidak sepenuhnya yakin mengapa titik akhir API diperlukan pada tahap ini karena tampaknya tidak muncul dalam generated talosconfigdan titik akhir yang ditentukan hanya 127.0.0.1. Sementara itu provided $CLUSTER_NAMEdigunakan untuk memberi nama konteks, jadi setidaknya masuk akal:
bahasa inggriscontext: kronform
contexts:
kronform:
endpoints:
- 127.0.0.1
ca: LS0t...
crt: LS0t...
key: LS0t...
Baik sertifikat bidang crtmaupun catidak berisi referensi ke titik akhir ini, dan saya kira tidak akan ada karena sertifikat ini untuk Kubernetes, dan ini berkaitan dengan API Talos.
Seperti halnya secrets.yamlberkas, konfigurasi klien ini juga sensitif.
Anda dapat menyalin berkas konfigurasi ini ke ~/.talos/configatau menggunakan talosctlperintah merge, yang tidak akan merusak konfigurasi apa pun yang mungkin Anda miliki:
pesta[mpd@ish]$ talosctl config merge ./talosconfig
Hasilkan MachineConfig pertama kita
Sekarang saatnya membuat konfigurasi mesin talos untuk node pertama kita!
... Tapi jangan terlalu cepat! Kita perlu sedikit menyesuaikannya. Sekarang kita dapat menggunakan talosctluntuk membuat controlplane.yamlkonfigurasi mesin generik dan kemudian memodifikasinya agar sesuai dengan kebutuhan kita, atau kita dapat menggunakan sistem patch sebagaimana dimaksudkan untuk membuat konfigurasi yang sudah jadi secara langsung.
Saya telah membuat beberapa direktori untuk melacak semua ini:
patches/di mana saya akan menempatkan patch di seluruh cluster,nodes/yang akan berisi file patch per node, dan akhirnyarendered/di mana saya akan menampilkan konfigurasi mesin yang telah selesai.
Pertama-tama, kita ingin mengaktifkan beban kerja pada mesin bidang kontrol kita. Server kita cukup kuat dan karena kita hanya akan menjalankan perangkat keras, kita memerlukan tempat untuk menjalankan beban kerja.
bahasa inggris# patches/allow-controlplane-workloads.yaml
cluster:
allowSchedulingOnControlPlanes: true
Kedua karena kita ingin menggunakan Cilium sebagai CNI kita, jadi kita perlu menonaktifkan CNI default dan menonaktifkannya kube-proxy, karena Cilium dilengkapi dengan penggantinya sendiri sesuai dengan dokumentasi Talos :
bahasa inggris# patches/disable-kube-proxy-and-cni.yaml
cluster:
network:
cni:
name: none
proxy:
disabled: true
Kami juga ingin mengganti nama cluster dan domain DNS. Ini sepenuhnya opsional, tetapi ada baiknya:
bahasa inggris# patches/cluster-name.yaml
cluster:
clusterName: kronform.pius.dev
network:
dnsDomain: local.kronform.pius.dev
Terakhir, kita perlu menambahkan beberapa penyesuaian untuk satu node kita (di sini bernama n1):
bahasa inggris# nodes/n1.yaml
machine:
install:
disk: none
diskSelector:
size: '< 1TB'
image: ghcr.io/siderolabs/installer:v1.4.4
network:
hostname: n1
interfaces:
- interface: eth0
dhcp: true
Peringatan: Jika dua atau lebih server Anda diberi alamat IPv4 dalam subnet /26 yang sama, DHCP tidak akan berfungsi untuk Anda! Lihat catatan 2
Saya menggunakan pemilih disk berbasis ukuran karena jalur perangkat dasar /dev/sdadan jalur bus perangkat dapat berubah di antara booting ulang, yang tidak ideal karena node kita dirancang untuk mencoba konvergen pada status yang kita inginkan, yang dalam beberapa keadaan dapat menyebabkan Talos menginstal ulang dirinya sendiri beberapa kali di beberapa perangkat.
Saya juga (sementara) melakukan hard-coding image untuk menggunakan Talos v1.4.4 sehingga kita dapat mencoba prosedur upgrade setelah berjalan. Anda harus menghilangkan baris ini ( image: ghcr...) dari konfigurasi Anda, jika Anda tidak peduli tentang itu.
Setelah semua selesai, saatnya untuk membuat konfigurasi mesin sebenarnya untuk node 3 kita :
pesta[mpd@ish]$ talosctl gen config \
--output rendered/n1.yaml \
--output-types controlplane \
--dns-domain local.$CLUSTER_NAME \
--with-cluster-discovery=false \
--with-secrets secrets.yaml \
--config-patch @patches/cluster-name.yaml \
--config-patch @patches/disable-kube-proxy-and-cni.yaml \
--config-patch @patches/allow-controlplane-workloads.yaml \
--config-patch @nodes/n1.yaml \
$CLUSTER_NAME \
$API_ENDPOINT
Konfigurasi sekarang dapat ditemukan dinodes/n1.yaml
Bootstrap Cluster
Tinjau konfigurasi yang diberikan rendered/n1.yamldan terapkan!
pesta[mpd@ish]$ talosctl --nodes 159.69.60.182 apply-config --file rendered/n1.yaml --insecure
Agak antiklimaks, kami sama sekali tidak mendapat respons. Untungnya, kami dapat menggunakan fungsi dasbor Talos untuk melihat apa yang terjadi:
pesta[mpd@ish]$ talosctl -n 159.69.60.182 dashboard
rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing: dial tcp 127.0.0.1:50000: connect: connection refused"
Benar. Kita talosconfigtidak tahu tentang titik akhirnya, jadi kita masukkan saja 127.0.0.1, mari kita perbaiki.
Dalam ~/.talos/configmenemukan endpointsarray...
bahasa inggris# ~/.talos/config (before)
context: kronform
contexts:
kronform:
endpoints:
- 127.0.0.1
# (...)
... Dan ganti 127.0.0.1dengan satu-satunya simpul kita 159.69.60.182:
bahasa inggris# ~/.talos/config (after)
context: kronform
contexts:
kronform:
endpoints:
- 159.69.60.182
# (...)
Ayo coba lagi!
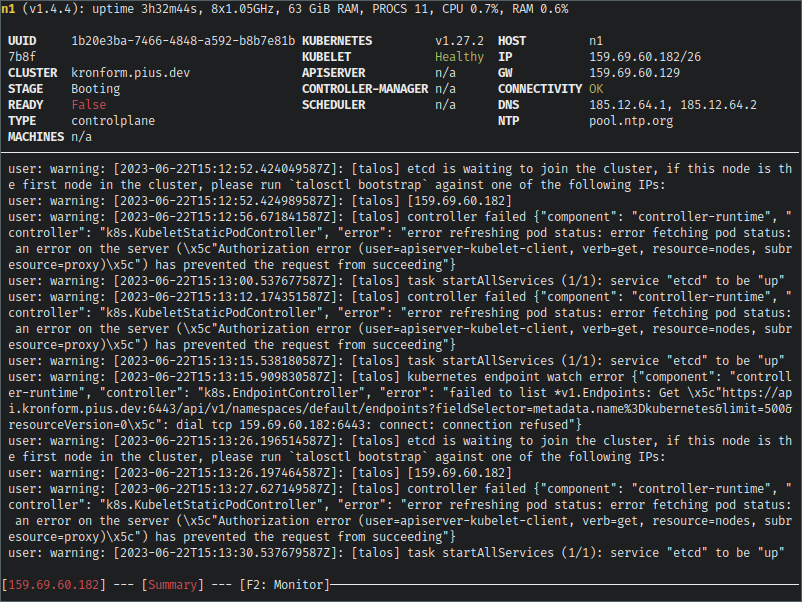
Keren! Jika kita gulir kembali ke atas log, kita dapat melihat bahwa konfigurasi telah diterapkan, dan STAGEtelah berubah menjadi Booting, yang sebelumnya adalah Maintenance.
Baru-baru ini di log, kita dapat melihat peringatan yang menunjukkan bahwa etcdsedang menunggu untuk bergabung dengan kluster. Ini adalah isyarat kita untuk memulai bootstrap kluster, jadi mari kita lanjutkan:
pesta[mpd@ish]$ talosctl --nodes 159.69.60.182 bootstrap
Saat melihat log dasbor bergulir, talos akan mulai mengeluarkan banyak sekali peringatan saat mulai menyesuaikan status yang diinginkan dari kluster yang baru di-bootstrap, dan memunculkan layanan.
Akhirnya akan tenang, dan READYstatus node akan berubah menjadi True, dan semua indikator layanan Kubernetes akan beralih ke Healthy.

Mari kita mulai ulang node tersebut dan lihat apakah instalasinya macet, atau apakah kita hanya mengulur-ulur waktu dalam memori.
Karena kami tidak memiliki akses SSH ke server, kami dapat meminta pengaturan ulang perangkat keras dari antarmuka Robot Hetzner, atau kami dapat meminta Talos melakukannya untuk kami.
pesta[mpd@ish]$ talosctl --nodes 159.69.60.182 reboot
Ini akan meluncurkan tampilan dinamis yang bagus mengenai status reboot, yang mungkin berguna jika Anda me-reboot beberapa node.
Node akan tampak berwarna hijau, berubah menjadi merah saat tidak tersedia, berubah menjadi kuning saat di-boot, dan akhirnya... Oh.
Tidak pernah berubah kembali menjadi hijau. Menarik. Dasbor Talos berfungsi, dan semua layanan Kubernetes aktif, jadi mari kita ekstrak kubeconfig dan lihat sendiri.
Perintah berikut akan membuat kubeconfig administrator sistem untuk klaster baru kita, menggabungkannya dengan klaster kita saat ini ~/.kube/configjika ada, dan secara otomatis menetapkan klaster kita sebagai konteks yang dipilih saat ini.
pesta[mpd@ish]$ talosctl -n 159.69.60.182 kubeconfig
pesta[mpd@ish]$ kubectl get nodes NAME STATUS ROLES AGE VERSION n1 NotReady control-plane 14m v1.27.2
Node kita ada , jadi itu bagus, tapi NotReady, kenapa?
pesta[mpd@ish]$ kubectl describe node n1 | grep NotReady
Ready False Thu, 22 Jun 2023 17:36:18 +0200 Thu, 22 Jun 2023 17:21:32 +0200 KubeletNotReady container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized
Duh. Kami belum memasang CNI!
Kita akan menganggap pekerjaan sudah selesai untuk saat ini, dan membahas instalasi CNI di posting berikutnya: Bagian II: Cilium CNI & Firewall
Epilog
Di sini saya mengumpulkan beberapa refleksi dan pembelajaran saya dari proses tersebut.
Setelah mengunci diri saya dari cluster saat menulis Bagian II: Cilium CNI & Firewall dari seri ini, saya mengalami masalah itu lagi dan menyadari bahwa server dimatikan karena saya menggunakan shutdown -halih-alih shutdown -r. Saya sepertinya ingat mencoba memulai server lagi sebagai bagian dari pemecahan masalah saya pertama kali, tetapi tentu saja saya tidak yakin.
Jaringan Hetzner sedikit aneh, seperti yang saya temukan baru-baru ini. Hetzner membagi pusat data mereka ke dalam subnet IPv4 /26, yang berarti setiap server khusus (jika IPv4 diaktifkan) diberi satu alamat dalam subnet /26, tetapi tidak diizinkan untuk berkomunikasi secara langsung dengan server lain dalam subnet ini, karena server tersebut dapat menjadi milik pelanggan lain dan (mungkin) melewati aturan firewall yang dapat Anda konfigurasikan melalui antarmuka Robot. Ini berarti bahwa jika dua atau lebih server Anda termasuk dalam subnet /26 yang sama, mereka tidak akan dapat berkomunikasi, karena mereka akan mencoba untuk berbicara satu sama lain secara langsung, bukan melalui gateway. Solusi untuk ini adalah dengan menetapkan alamat secara statis sebagai alamat /32, mengarahkan lalu lintas 0.0.0.0/32 ke gateway, lalu menentukan rute langsung lain ke gateway itu sendiri. Tanpa rute terakhir, kernel akan menolak untuk mengizinkan Anda mengonfigurasi gateway, karena berada di luar jaringannya sendiri (jaringannya sendiri yang terdiri dari satu alamat /32). Contoh konfigurasinya mungkin terlihat seperti ini, dengan asumsi server memiliki 123.123.123.123/26gateway 123.123.123.65:
bahasa inggrismachine:
network:
interfaces:
- interface: eth0
dhcp: flase
addresses:
- 123.123.123.123/32
routes:
- network: "123.123.123.65/32" # Direct route to gateway
- network: "0.0.0.0/0"
gateway: "123.123.123.65"
Bahasa Indonesia: Melakukan diffing konfigurasi mesin Intuisi saya mengenai diffing machineconfigs sebagian benar. Ketika mengambil machineconfigs dari Talos, mereka sebenarnya berisi komentar, tetapi dokumen yang dikembalikan mirip dengan sumber daya kustom tempat konfigurasi bersarang di dalamnya .specyang berarti Anda perlu menyalurkan konfigurasi melalui alat seperti yquntuk mendapatkan dokumen itu sendiri, sebuah proses yang juga menghapus komentar. Dokumen yaml yang dihasilkan oleh talosctl gen configmenggunakan indentasi 4 spasi, sedangkan konfigurasi sebagai ekstrak dari talosctlmenggunakan indentasi 2 spasi, yang berarti konfigurasi asli yang dirender harus diteruskan yq(seperti yang lain) untuk memastikan format yang identik, jika tidak, diff menjadi tidak berguna. Saya pikir cara teraman untuk berinteraksi dengan machineconfigs adalah kombinasi dari penggunaan alat bawaan untuk tindakan umum seperti peningkatan di mana gambar diganti, dan kemudian menggunakan talosctl edit machineconfiguntuk semua yang lain, pastikan untuk mengambil cadangan sebelum dan setelah setiap perubahan.
Tidak ada komentar:
Posting Komentar