https://www.mydbops.com/blog/postgresql-cascading-replication/
Streaming replication in PostgreSQL involves creating an active copy of a database on a database instance. This copy, commonly called a replica, stays current with any changes made to the original database.
Replication serves several functions, including enhancing system reliability, providing backup alternatives, and distributing the workload across multiple servers to enhance overall performance. Replication in PostgreSQL is crucial to improving the availability, fault tolerance, load balancing, and scalability of a database system. With more replicas, multiple copies of the data are distributed across different servers. If one server fails, others can continue to serve the application, improving overall system availability.
Also read: Bidirectional Logical Replication in PostgreSQL 16 |
Challenges in Scaling Up
Now, in the case of scaling up the DB cluster and adding new replicas to an existing DB cluster, it is required to set up streaming replication from the primary server. However, if the primary server is busy, starting up a new streaming replication process will impact server performance. Therefore, we can use the cascading replication technique in PostgreSQL (introduced from PostgreSQL version 9.2) to set up replication from a secondary (replica) server.
In this blog post, we will explore what cascading replication is and how to configure it.
Understanding Cascading Replication
Cascading replication in PostgreSQL is a database configuration where replicas replicate from other replica servers instead of a primary server, forming a hierarchical chain. This feature allows a standby server to act as a relay for streaming Write-Ahead Logging (WAL) records to other standby servers.
Configuring cascading replication in a database system involves setting up a hierarchy of replication servers, where replicas replicate from other replicas rather than directly from the primary server. This lessens the direct burden on the primary server, as replicas handle the task of transmitting changes throughout the replication chain.
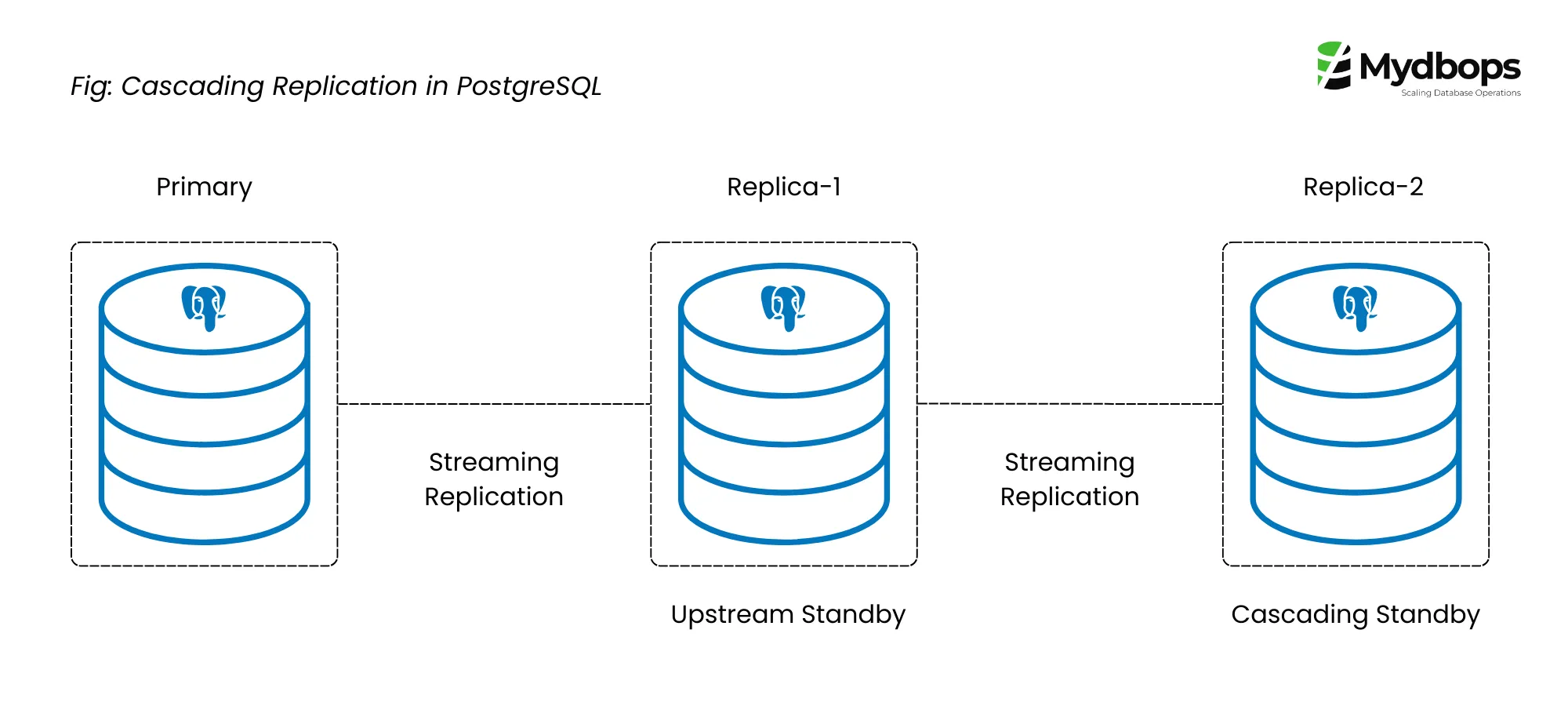
The following is the step-by-step mechanism of the working of cascading replication:
Primary server: The primary server generates WAL records as a result of data changes.
Upstream Standby Server (replica-1): These WAL records are streamed to an upstream standby server, which applies the changes to stay in sync with the primary.
Cascading Standby Server (replica-2): The upstream standby can then relay, or cascade, these WAL records to one or more downstream standby servers. The cascading standby server acts as both a receiver from the primary and a sender to other standbys.
Cascading replication can be configured without restrictions on the number or arrangement of downstream servers.
Operating asynchronously, it remains unaffected by synchronous replication settings. It ensures continuous data replication even if the direct connection from the upstream to the primary is disrupted, as long as new Write-Ahead Logging (WAL) records are accessible.
Advantages of Cascading Replication
Reduces the primary server's load by minimizing the number of direct connections to it.
Optimizes bandwidth usage across sites by enabling downstream servers to receive Write-Ahead Logging (WAL) data from a geographically closer upstream standby.
In the event of the promotion of an upstream standby to the primary role, downstream standbys can seamlessly stream from the new primary, provided that recovery_target_timeline is set to latest, the default setting.
Improves scalability by distributing replication traffic among multiple standbys.
Offers greater flexibility in designing replication topologies for various deployment scenarios.
Increases the availability of the data throughout the hosted regions.
Demo: Setting up Cascading Replication
The following is a tutorial for setting up cascading replication from an existing replica server:
Here, we will use three servers to initialize three database servers.
Primary server:
postgres=# select * from pg_stat_replication ;
-[ RECORD 1 ]----+------------------------------
pid | 2811
usesysid | 16385
usename | repuser
application_name | walreceiver
client_addr | 192.168.33.22
client_hostname |
client_port | 44010
backend_start | 2023-12-08 11:25:10.188293+00
backend_xmin |
state | streaming
sent_lsn | 0/3000060
write_lsn | 0/3000060
flush_lsn | 0/3000060
replay_lsn | 0/3000060
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2023-12-08 11:25:50.349485+00Replica-1 server:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)To create another cascading replica, we will install and start an additional database server (with the same version as the current primary and replica-1) on Server 3.
/usr/lib/postgresql/14/bin/initdb -D /home/test/db3Once initialized, we need to clear the data directory, i.e., /home/test/db3, to take a new base backup. Here, we will take the base backup from the existing replica-1 server instead of the primary server.
Note: Ensure that the IP and user for replication of the new replica-2 server are added in the pg_hba.conf file on the replica-1 server.
Replica-1 pg_hba.conf:
host replication repuser 192.168.33.23/32 md5We will use the pg_basebackup utility that comes from the PostgreSQL installation to take a base backup:
/usr/lib/postgresql/14/bin/pg_basebackup -h 192.168.33.22 -p 5432 -D /home/test/db3 -U repuser -P -v -R -X stream -C -S slot2We are taking the base backup from the replica-1 server, utilizing the repuser for replication. Additionally, we are creating a new replication slot, namely slot2 for the replication process. This slot will be created on the current replica-1 server. The -D flag defines the directory where we need to initiate the new database server.
Once the base backup is completed, we can proceed to start the database instance on server 3:
/usr/lib/postgresql/14/bin/pg_ctl start -D /home/test/db3We can then verify the replication configuration from replica-1:
postgres=# select pg_is_in_recovery();
-[ RECORD 1 ]-----+--
pg_is_in_recovery | t
postgres=# select * from pg_replication_slots;
-[ RECORD 1 ]-------+----------
slot_name | slot2
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 2988
xmin |
catalog_xmin |
restart_lsn | 0/3019F58
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |
two_phase | fHere, we can observe that the replica-1 server is in recovery mode since it is a replica of the primary server. Additionally, we can view the replication statistics configured from replica-1 to replica-2
Replica-2:
postgres=# select pg_is_in_recovery();
-[ RECORD 1 ]-----+--
pg_is_in_recovery | tThe replica-2 server is in recovery mode as it replicates the replica-1 server.
This concludes the setup of cascading replication. We can add more replicas to the cluster using the cascading replication method, creating replicas from the existing replica servers.
In summary, implementing cascading replication is a strategic method to enhance database efficiency. This is achieved by distributing the replication load, optimizing bandwidth usage, and enabling scalability, resulting in improved fault tolerance and geographic distribution. The flexible topology ensures adaptability to changing requirements. Nonetheless, database engineers should exercise caution due to the increased complexity of overseeing the replication hierarchy.
We offer specialized Managed and Consulting services for Open source databases. Connect with us to optimize your database environment and ensure peak performance. Contact Mydbops Now for expert support tailored to your needs.
Tidak ada komentar:
Posting Komentar