Elkar Backup
Don't be like Cameron. Backup your stuff.
ElkarBackup is a free open-source backup solution based on RSync/RSnapshot. It's basically a web wrapper around rsync/rsnapshot, which means that your backups are just files on a filesystem, utilising hardlinks for tracking incremental changes. I find this result more reassuring than a blob of compressed, (encrypted?) data that more sophisticated backup solutions would produce for you.
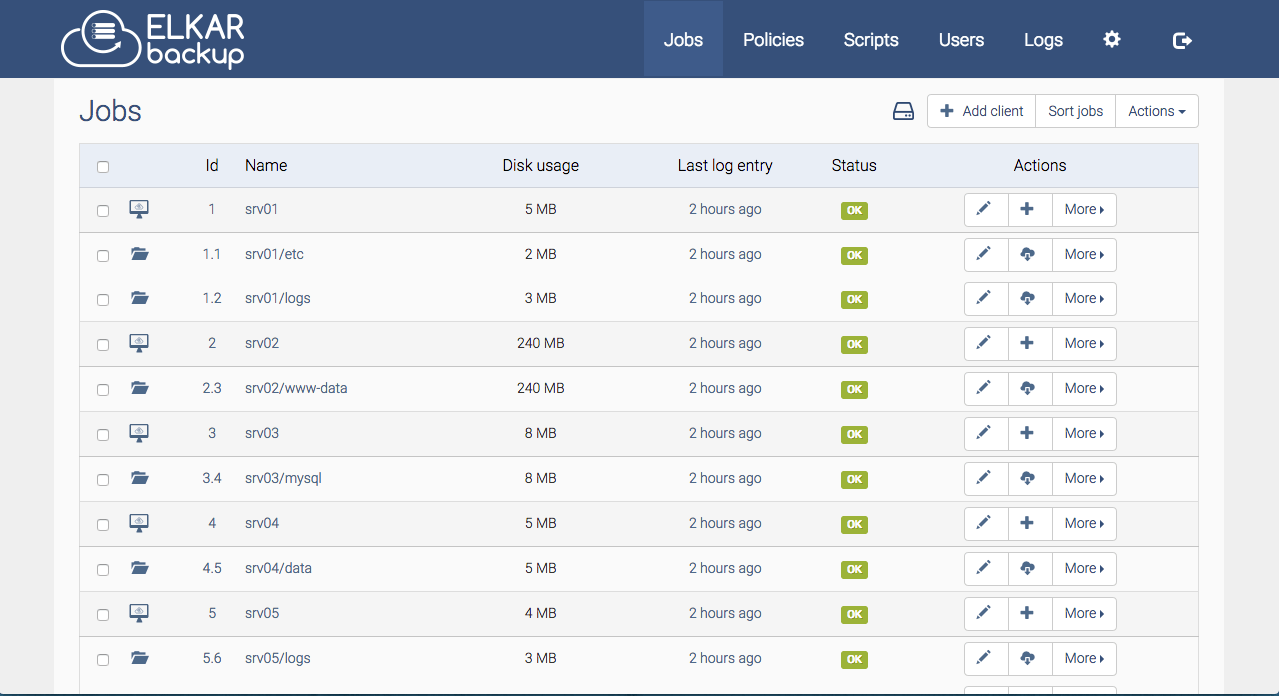
Elkar Backup Requirements
Ingredients
Already deployed:
- Docker swarm cluster with persistent shared storage
- Traefik configured per design
- DNS entry for the hostname you intend to use (or a wildcard), pointed to your keepalived IP
Related:
- Traefik Forward Auth or Authelia to secure your Traefik-exposed services with an additional layer of authentication
Preparation
Setup data locations
We'll need several directories to bind-mount into our container, so create them in /var/data/elkarbackup:
mkdir -p /var/data/elkarbackup/{backups,uploads,sshkeys,database-dump}
mkdir -p /var/data/runtime/elkarbackup/db
mkdir -p /var/data/config/elkarbackup
Prepare Elkar Backup environment
Create /var/data/config/elkarbackup/elkarbackup.env, and populate with the following variables
SYMFONY__DATABASE__PASSWORD=password
EB_CRON=enabled
TZ='Etc/UTC'
#SMTP - Populate these if you want email notifications
#SYMFONY__MAILER__HOST=
#SYMFONY__MAILER__USER=
#SYMFONY__MAILER__PASSWORD=
#SYMFONY__MAILER__FROM=
# For mysql
MYSQL_ROOT_PASSWORD=password
Create /var/data/config/elkarbackup/elkarbackup-db-backup.env, and populate with the following, to setup the nightly database dump.
Note
Running a daily database dump might be considered overkill, since ElkarBackup can be configured to backup its own database. However, making my own backup keeps the operation of this stack consistent with other stacks which employ MariaDB.
Also, did you ever hear about the guy who said "_I wish I had fewer backups"?
No, me either 
# For database backup (keep 7 days daily backups)
MYSQL_PWD=<same as SYMFONY__DATABASE__PASSWORD above>
MYSQL_USER=root
BACKUP_NUM_KEEP=7
BACKUP_FREQUENCY=1d
Elkar Backup Docker Swarm config
Create a docker swarm config file in docker-compose syntax (v3), something like the example below:
Fast-track with premix! 🚀
I automatically and instantly share (with my sponsors) a private "premix" git repository, which includes necessary docker-compose and env files for all published recipes. This means that sponsors can launch any recipe with just a git pull and a docker stack deploy 👍.
🚀 Update: Premix now includes an ansible playbook, so that sponsors can deploy an entire stack + recipes, with a single ansible command! (more here)
version: "3"
services:
db:
image: mariadb:10.4
env_file: /var/data/config/elkarbackup/elkarbackup.env
networks:
- internal
volumes:
- /etc/localtime:/etc/localtime:ro
- /var/data/runtime/elkarbackup/db:/var/lib/mysql
db-backup:
image: mariadb:10.4
env_file: /var/data/config/elkarbackup/elkarbackup-db-backup.env
volumes:
- /var/data/elkarbackup/database-dump:/dump
- /etc/localtime:/etc/localtime:ro
entrypoint: |
bash -c 'bash -s <<EOF
trap "break;exit" SIGHUP SIGINT SIGTERM
sleep 2m
while /bin/true; do
mysqldump -h db --all-databases | gzip -c > /dump/dump_\`date +%d-%m-%Y"_"%H_%M_%S\`.sql.gz
(ls -t /dump/dump*.sql.gz|head -n $$BACKUP_NUM_KEEP;ls /dump/dump*.sql.gz)|sort|uniq -u|xargs rm -- {}
sleep $$BACKUP_FREQUENCY
done
EOF'
networks:
- internal
app:
image: elkarbackup/elkarbackup
env_file: /var/data/config/elkarbackup/elkarbackup.env
networks:
- internal
- traefik_public
volumes:
- /etc/localtime:/etc/localtime:ro
- /var/data/:/var/data
- /var/data/elkarbackup/backups:/app/backups
- /var/data/elkarbackup/uploads:/app/uploads
- /var/data/elkarbackup/sshkeys:/app/.ssh
deploy:
labels:
# traefik common
- traefik.enable=true
- traefik.docker.network=traefik_public
# traefikv1
- traefik.frontend.rule=Host:elkarbackup.example.com
- traefik.port=80
# traefikv2
- "traefik.http.routers.elkarbackup.rule=Host(`elkarbackup.example.com`)"
- "traefik.http.services.elkarbackup.loadbalancer.server.port=80"
- "traefik.enable=true"
# Remove if you wish to access the URL directly
- "traefik.http.routers.elkarbackup.middlewares=forward-auth@file"
networks:
traefik_public:
external: true
internal:
driver: overlay
ipam:
config:
- subnet: 172.16.36.0/24
Note
Setup unique static subnets for every stack you deploy. This avoids IP/gateway conflicts which can otherwise occur when you're creating/removing stacks a lot. See my list here.
Serving
Launch ElkarBackup stack
Launch the ElkarBackup stack by running docker stack deploy elkarbackup -c <path -to-docker-compose.yml>
Log into your new instance at https://YOUR-FQDN, with user "root" and the password default password "root":
First thing you do, change your password, using the gear icon, and "Change Password" link:
Have a read of the Elkarbackup Docs - they introduce the concept of clients (hosts containing data to be backed up), jobs (what data gets backed up), policies (when is data backed up and how long is it kept).
At the very least, you want to setup a client called "localhost" with an empty path (i.e., the job path will be accessed locally, without SSH), and then add a job to this client to backup /var/data, excluding /var/data/runtime and /var/data/elkarbackup/backup (unless you like "backup-ception")
Copying your backup data offsite
From the WebUI, you can download a script intended to be executed on a remote host, to backup your backup data to an offsite location. This is a Good Idea™, but needs some massaging for a Docker swarm deployment.
Here's a variation to the standard script, which I've employed:
#!/bin/bash
REPOSITORY=/var/data/elkarbackup/backups
SERVER=<target host member of docker swarm>
SERVER_USER=elkarbackup
UPLOADS=/var/data/elkarbackup/uploads
TARGET=/srv/backup/elkarbackup
echo "Starting backup..."
echo "Date: " `date "+%Y-%m-%d (%H:%M)"`
ssh "$SERVER_USER@$SERVER" "cd '$REPOSITORY'; find . -maxdepth 2 -mindepth 2" | sed s/^..// | while read jobId
do
echo Backing up job $jobId
mkdir -p $TARGET/$jobId 2>/dev/null
rsync -aH --delete "$SERVER_USER@$SERVER:$REPOSITORY/$jobId/" $TARGET/$jobId
done
echo Backing up uploads
rsync -aH --delete "$SERVER_USER@$SERVER":"$UPLOADS/" $TARGET/uploads
USED=`df -h . | awk 'NR==2 { print $3 }'`
USE=`df -h . | awk 'NR==2 { print $5 }'`
AVAILABLE=`df -h . | awk 'NR==2 { print $4 }'`
echo "Backup finished succesfully!"
echo "Date: " `date "+%Y-%m-%d (%H:%M)"`
echo ""
echo "**** INFO ****"
echo "Used disk space: $USED ($USE)"
echo "Available disk space: $AVAILABLE"
echo ""
Note
You'll note that I don't use the script to create a mysql dump (since Elkar is running within a container anyway), rather I just rely on the database dump which is made nightly into /var/data/elkarbackup/database-dump/
Restoring data
Repeat after me : "It's not a backup unless you've tested a restore"
Note
I had some difficulty making restoring work well in the webUI. My attempts to "Restore to client" failed with an SSH error about "localhost" not found. I was able to download the backup from my web browser, so I considered it a successful restore, since I can retrieve the backed-up data either from the webUI or from the filesystem directly.
To restore files form a job, click on the "Restore" button in the WebUI, while on the Jobs tab:
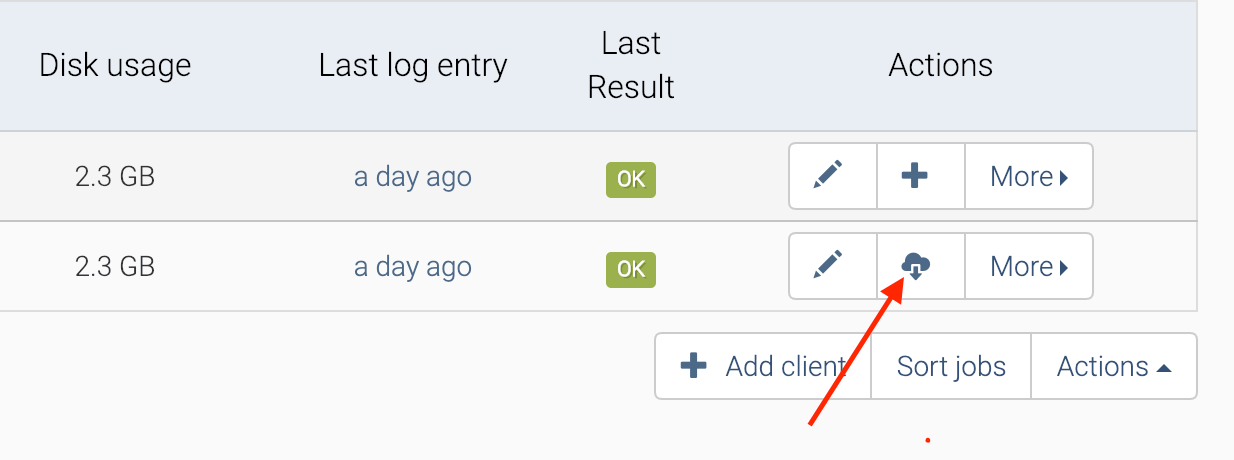
This takes you to a list of backup names and file paths. You can choose to download the entire contents of the backup from your browser as a .tar.gz, or to restore the backup to the client. If you click on the name of the backup, you can also drill down into the file structure, choosing to restore a single file or directory.
Tidak ada komentar:
Posting Komentar