Klaster Proxmox Ketersediaan Tinggi (HA): Yang Harus dan Tidak Boleh Dilakukan
Salah satu fitur paling canggih dalam menjalankan klaster virtualisasi adalah kemampuannya untuk memiliki fitur ketersediaan tinggi yang terintegrasi ke dalam solusinya. Fitur ketersediaan tinggi memungkinkan Anda menjalankan mesin virtual dengan cara yang membuatnya tangguh terhadap kegagalan host. Proxmox memiliki fitur-fitur ini yang terintegrasi dengan fitur klaster HA yang dimilikinya. Namun, tentu saja ada beberapa kekurangan yang perlu diperhatikan dalam penggunaan HA Proxmox. Mari kita lihat apa yang boleh dan tidak boleh dilakukan dalam pengelompokan HA di Proxmox dan lihat apa yang bisa kita pelajari.
Apa itu Proxmox HA?
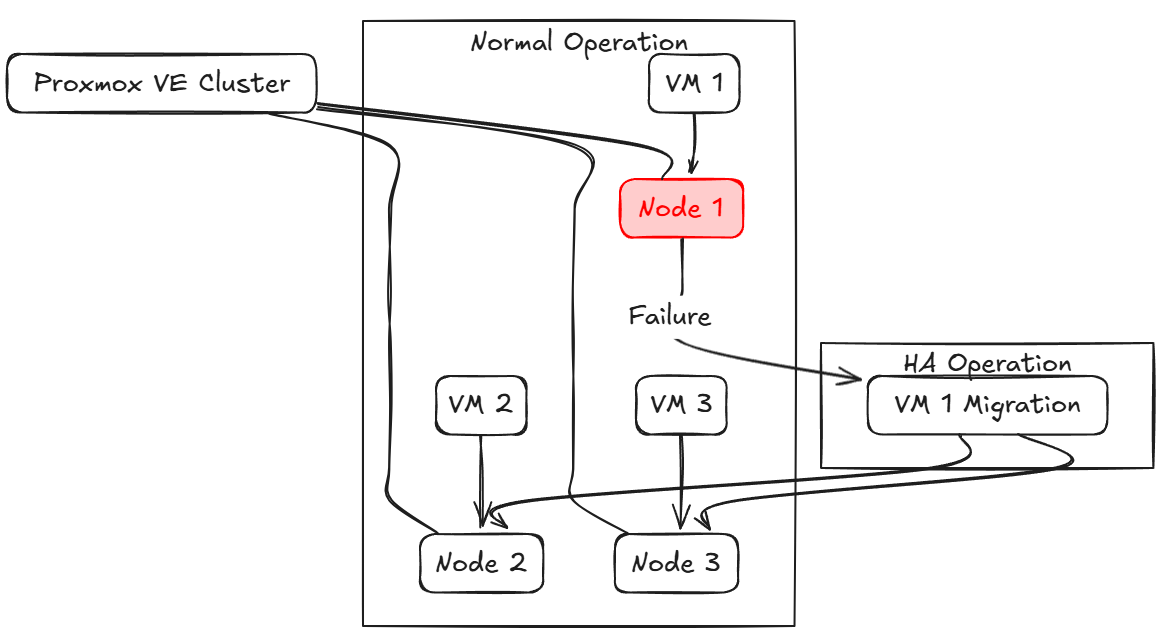
Pertama-tama, mari kita bahas apa itu Proxmox HA. Dengan HA, artinya Anda memiliki lebih dari satu host klaster di klaster Proxmox yang memiliki semacam penyimpanan bersama untuk mesin virtual Anda. Jika salah satu host klaster mati secara tiba-tiba, VM yang dikonfigurasi dengan HA akan diaktifkan di host yang masih berfungsi di klaster tersebut.
Selain itu, ini memberi Anda kemampuan untuk menonaktifkan node Proxmox secara proaktif untuk pemeliharaan dan patching bila diperlukan. Ini sangat bagus karena kita tidak perlu lagi memiliki waktu pemeliharaan di luar jam kerja untuk menambal host yang mendasarinya. Kita dapat melakukan ini tanpa sepengetahuan siapa pun.
Membantu bahkan di laboratorium rumah
Bahkan di lab rumahan, Anda mungkin menjalankan layanan yang tidak ingin Anda hentikan, seperti Asisten Rumah atau server media Anda. Anda juga dapat menjalankan server Git yang dihosting sendiri untuk kode DevOps atau lingkungan pembelajaran atau pengujian yang harus tetap aktif selama CI/CD dijalankan.
Jika Anda memiliki 3 PC mini yang berjalan di kluster HA di Proxmox, jika salah satunya gagal, VM akan dihidupkan ulang di salah satu dari dua PC mini yang sehat.
Merencanakan klaster HA Proxmox
Ada beberapa hal yang perlu Anda ketahui dan persyaratan yang harus dipenuhi saat merencanakan klaster Proxmox HA. Perhatikan hal-hal berikut:
- Minimal tiga node : Untuk menjaga kuorum dan menghindari split-brain, Proxmox merekomendasikan setidaknya tiga node klaster. Mereka memang memiliki klaster dua node yang dapat bekerja dengan perangkat kuorum eksternal, tetapi 3 node tetap menjadi rekomendasi di sini.
- Penyimpanan bersama : HA bergantung pada semua node yang melihat penyimpanan dasar yang sama. Anda dapat menggunakan penyimpanan NFS, iSCSI, atau Ceph HCI sebagai penyimpanan bersama yang memungkinkan Anda memiliki konfigurasi HA yang efektif untuk klaster Anda.
- Jaringan yang stabil untuk proses corosync : Komunikasi klaster Proxmox (corosync) membutuhkan jaringan yang andal dan berlatensi rendah. Kehilangan paket atau jitter yang tinggi dapat menyebabkan pengusiran node atau perilaku klaster yang tidak andal lainnya.
- Waktu tersinkronisasi : Pastikan semua node menjalankan NTP (atau chrony) pada konfigurasi server waktu yang sama. Penyimpangan waktu dapat mengganggu keputusan fencing dan HA.
Setelah dasar-dasar ini dipahami, Anda siap untuk mendalami apa yang boleh dan apa yang tidak boleh dilakukan.
Apa yang “Harus Dilakukan” dengan Cluster HA Proxmox
Berikut adalah beberapa hal yang harus dilakukan saat mengonfigurasi dan menyiapkan kluster HA Proxmox.
Atur VM ke dalam grup HA dan tetapkan prioritas
Pertama-tama, apa itu grup HA? Di Proxmox, grup HA adalah kumpulan VM atau kontainer yang memiliki persyaratan HA serupa. Dengan menetapkan VM ke grup HA, Anda dapat melakukan hal berikut:
- Kontrol urutan startup : Pastikan layanan penting seperti server database selalu dimulai sebelum VM dependen, seperti server aplikasi
- Terapkan aturan anti-afinitas : Cegah dua replika layanan yang sama berjalan pada host fisik yang sama—mengurangi risiko kegagalan simultan.
- Tetapkan prioritas failover : Tentukan VM mana yang mendapatkan sumber daya terlebih dahulu jika beberapa host gagal secara bersamaan.
Praktik terbaik: Buat grup untuk critical-coresistem terpenting Anda, dan low-priorityuntuk VM uji yang tidak penting. Kemudian, di Pusat Data → HA → Grup , Anda dapat menetapkan setiap VM dan mengonfigurasi kolom "Relokasi Maksimum" dan "Urutan" agar sesuai dengan rencana pemulihan Anda.
Konfigurasikan pagar
Fencing adalah istilah yang aneh, tetapi artinya ("Tembak Kepala Node Lain"). Fencing memungkinkan Anda mengisolasi atau mematikan node yang gagal agar tidak merusak data bersama. Tanpanya, dua node mungkin merasa bahwa mereka memiliki disk VM. Ini sangat buruk dan dapat menyebabkan split-brain dan data rusak atau hilang.
- Semua konfigurasi pagar berada di bawah
/etc/pve/ha/dan dikelola oleh layanan fence-proxy . Di GUI, Anda dapat menemukannya di Pusat Data → HA → Pagar , dan setiap perubahan akan secara otomatis dikirim ke setiap node Proxmox VE . - Cluster tidak lagi digunakan
cluster.confuntuk fencing (itu hanya di Proxmox VE 3.x atau versi lama lainnya).
1. Pasang agen pagar
Pada setiap node, instal paket Debian standar untuk mendapatkan agen pagar OCF:
apt update && apt install fence-agents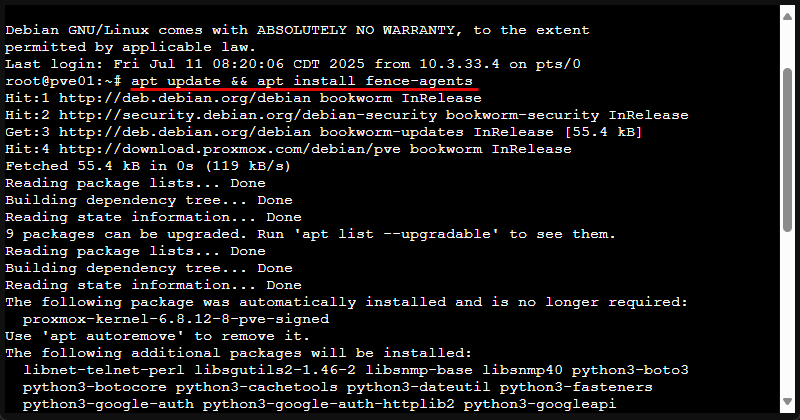
Ini menyediakan agen seperti fence_ipmilan, fence_drac5, fence_apc, dll.
2. Tambahkan perangkat pagar melalui GUI atau API
- GUI: Buka Pusat Data → HA → Pagar → Tambah , pilih agen Anda, berikan alamat IP, kredensial, dan nama yang mudah diingat.
- CLI/API:
pvesh create /nodes/<node>/fence \ --device agent=fence_ipmilan,lanplus=1,ipaddr=10.0.0.30,login=admin,passwd=secret,power_wait=10Ini menuliskan perangkat Anda/etc/pve/ha/fence.cfgdan mereplikasinya di seluruh kluster.
3. Verifikasi mode anggar
Buka /etc/pve/datacenter.cfg(atau lihat Pusat Data → HA → Opsi ) dan konfirmasikan fencing:pengaturannya—opsinya adalah watchdog(default), hardware, atau both. Mode perangkat keras menggunakan perangkat pagar yang telah Anda konfigurasikan.
4. Uji aksi pagar Anda
Selalu simulasikan pagar untuk memastikan pengoperasian yang tepat:
pvesh create /nodes/<node>/fencePerhatikan daya simpul target mati (atau disetel ulang) dan periksa /var/log/syslogatau gunakan journalctl -u pve-ha-lrmuntuk mengonfirmasi tindakan berhasil.
Integrasikan pemantauan proaktif
Tindakan HA hanya melengkapi kemampuan Anda untuk mendeteksi masalah. Pemantauan yang tepat dapat membantu mendeteksi masalah sebelum meluas. Partisi Corosync, lonjakan latensi penyimpanan, atau masalah perangkat keras host dapat menyebabkan masalah, tetapi dapat dipantau. Pertimbangkan untuk memantau hal-hal berikut di Proxmox:
- Kesehatan Corosync : Jumlah node cluster, latensi pulang pergi, kehilangan paket
- Metrik penyimpanan : IOPS, latensi baca/tulis, throughput jaringan ke penyimpanan bersama
- Sumber daya host : Beban CPU, tekanan memori, saturasi disk
Cara penerapan:
- Hubungkan notifikasi bawaan Proxmox ke email atau Slack.
- Gunakan alat seperti Prometheus + Node Exporter dengan dasbor Grafana yang berfokus pada metrik kluster dan penyimpanan.
- Konfigurasikan ambang batas peringatan (misalnya, latensi corosync >10 ms selama >1 menit) untuk mendeteksi tanda-tanda awal masalah.
Jadwalkan failover untuk menguji
Otomatisasi hanya berfungsi jika telah diuji dalam kondisi nyata. Kapan terakhir kali Anda melakukan failover secara sengaja? Jalankan pengujian dengan cara ini:
- Pilih jendela pemeliharaan.
- Di GUI atau CLI Proxmox, nonaktifkan HA pada satu node atau simulasikan kegagalan daya
- Perhatikan proses evakuasi VM Anda. Apakah VM tersebut memulai ulang di host lain?
- Periksa log HA (
/var/log/pve-ha-manager.log) untuk kesalahan atau masalah lainnya - Dokumentasikan setiap langkah manual atau masalah yang Anda temukan
Pastikan versi perangkat lunak cluster tetap sinkron
Corosync adalah layanan pengelompokan yang menjalankan Proxmox HA. Layanan ini sensitif terhadap ketidakcocokan versi Proxmox. Bahkan patch kecil pun dapat mengubah hal-hal yang memutus komunikasi. Hal ini dapat menyebabkan masalah failover atau memicunya secara keliru.
- Rencanakan peningkatan Proxmox Anda sehingga Anda meningkatkan semua node dalam jendela pemeliharaan yang sama
- Periksa versi paket (
apt list --installed pve-cluster corosync) sebelum dan setelah pemutakhiran - Gunakan pendekatan peningkatan bergulir – Lakukan pengurasan satu node pada satu waktu, tingkatkan, pastikan kesehatan cluster Anda, lalu pindah ke node berikutnya
Praktik terbaik yang ingin saya lakukan: Menjaga log perubahan yang mencatat tanggal pemutakhiran, versi paket, dan langkah pasca pemutakhiran (misalnya, memulai ulang pve-ha-manager).
Apa yang “Tidak Boleh” Dilakukan dengan Proxmox HA
Ingatlah hal-hal “larangan” berikut saat Anda mengonfigurasi dan mengelola kluster Proxmox HA Anda.

Jangan bergantung pada jaringan yang tidak stabil untuk komunikasi cluster
HA Proxmox bergantung pada corosync untuk pesan detak jantung antar node. Jika paket terputus atau tertunda, bahkan hanya sesaat, pada node yang sehat, hal ini dapat menyebabkan failover atau pengusiran node yang tidak perlu. Berikut hal-hal yang harus dihindari:
- Adaptor nirkabel atau kabel listrik : Ini mungkin digunakan di lingkungan lab rumah, tetapi jangan gunakan nirkabel jika Anda dapat menghindarinya
- Kabel jaringan tunggal : Port yang terputus atau rusak akan langsung membuat tautan corosync Anda offline, jadi pertimbangkan untuk melakukan bonding
- Kecepatan campuran pada satu koneksi : Hindari menggabungkan antarmuka 1 GbE dan 2,5 GbE dalam satu koneksi. Tautan yang lebih lambat atau tautan yang tidak cocok dapat menyebabkan keanehan.
Gunakan setidaknya dua koneksi kabel yang identik untuk corosync, dan konfigurasikan keduanya dalam ikatan aktif/cadangan sehingga satu kegagalan tidak akan mengganggu bus klaster. Lihat postingan saya tentang praktik terbaik jaringan Proxmox di sini:
Jangan abaikan kinerja penyimpanan Anda
Selama failover, VM bermigrasi langsung atau memulai ulang di host baru. Kedua hal ini dapat menyebabkan operasi baca dan tulis yang berat pada penyimpanan bersama Anda. Pastikan array Anda tidak jenuh saat VM dimulai ulang. Beberapa hal yang perlu diperhatikan yang mungkin mengindikasikan adanya bottleneck pada penyimpanan:
- Migrasi langsung tergantung pada 1%–5% selama beberapa menit
- Kesalahan “Waktu habis menunggu migrasi” di log HA
- Lonjakan latensi yang memicu kegagalan node palsu
Pastikan untuk membandingkan solusi penyimpanan Anda dengan alat seperti Fio. Targetkan latensi di bawah 10 ms dan throughput yang melebihi skenario terburuk Anda (misalnya, 5 pemindahan VM secara bersamaan).
Jangan mengambil node offline tanpa menyesuaikan kuorum
Proxmox menggunakan sistem voting mayoritas (kuorum) untuk memastikan kesehatan klaster dalam kondisi baik. Dalam klaster dengan tiga node, kehilangan dua node sekaligus akan menurunkan kuorum menjadi 33%, sehingga node yang tersisa terpaksa melepaskan kendali klaster.
- Pemeliharaan yang anggun: Gunakan
pvecm expected 2tindakan “Shutdown” GUI, yang memberi tahu corosync bahwa Anda sengaja menghapus node sehingga dapat menyesuaikan kuorum. - Pemecah masalah eksternal: Dalam kluster dua node, konfigurasikan QDevice atau server “saksi” ketiga untuk mempertahankan kuorum jika satu node mati.
Jangan membebani host secara berlebihan
Jika node sehat Anda sudah menggunakan CPU, RAM, atau jaringan sebesar 90–100%, node tersebut tidak akan dapat menerima VM atau kontainer tambahan dari host yang gagal. Pastikan untuk merencanakan ruang bebas ini yang diperlukan untuk menjalankan beban kerja jika host mengalami kegagalan. Anda juga dapat melakukan hal-hal berikut:
- Tetapkan batas HA: Dalam pengaturan HA untuk setiap VM, tentukan jumlah “Relokasi Maksimum” sehingga hanya sejumlah VM yang aman yang dapat dipindahkan secara bersamaan.
- Sisihkan kapasitas sebagai penyangga: Usahakan menjalankan klaster Anda tidak lebih dari 70% beban keseluruhan, dan sisakan 30% sebagai cadangan untuk peristiwa failover.
Anda dapat menggunakan tampilan “Sumber Daya → Ringkasan” di Proxmox untuk melacak pemanfaatan klaster dan merencanakan peningkatan kapasitas sebelum mencapai ambang batas kritis.
Jangan lewatkan tinjauan log setelah kejadian HA apa pun
Ketika failover terjadi, bahkan selama gangguan corosync, Anda dapat menemukan petunjuk di /var/log/pve-ha-manager.logdan /var/log/syslog. Pastikan untuk memeriksa berkas-berkas ini agar Anda tidak melewatkan kegagalan berulang atau kesalahan konfigurasi yang mungkin terjadi. Ada beberapa hal yang perlu diperhatikan di sana:
- Peringatan otak terbelah Corosync (“Detak jantung hilang dari simpul…”).
- Kesalahan migrasi (“migrasi ke node gagal: waktu habis”).
Menyimpulkan
Salah satu keunggulan menjalankan kluster virtualisasi adalah kemampuannya untuk mengonfigurasi ketersediaan tinggi untuk mesin virtual dan kontainer LXC Anda. Jika terjadi kegagalan node, Anda tentu tidak ingin hidup dalam kesulitan. Anda tentu ingin memiliki cara untuk memiliki ketahanan bagi aplikasi dan beban kerja yang Anda hosting sendiri di lab rumah atau aplikasi yang Anda jalankan dalam produksi. Seperti halnya apa pun, ada hal yang boleh dan tidak boleh dilakukan saat menjalankan Proxmox VE Server HA yang perlu diperhatikan. Semoga daftar periksa ini dapat membantu mengidentifikasi area-area penting yang perlu diperhatikan.
Tidak ada komentar:
Posting Komentar