Replikasi PostgreSQL untuk Pemulihan Bencana

Dengan Pemulihan Bencana, kami bertujuan untuk menyiapkan sistem untuk menangani apa pun yang bisa salah dengan database kami. Apa yang terjadi jika database crash? Bagaimana jika pengembang secara tidak sengaja memotong tabel? Bagaimana jika kami mengetahui beberapa data telah dihapus minggu lalu tetapi kami tidak menyadarinya sampai hari ini? Hal-hal ini terjadi, dan memiliki rencana dan sistem yang solid akan membuat DBA terlihat seperti pahlawan ketika hati semua orang telah berhenti ketika bencana muncul.
Basis data apa pun yang memiliki nilai apa pun harus memiliki cara untuk mengimplementasikan satu atau lebih opsi Pemulihan Bencana. PostgreSQL memiliki sistem replikasi yang sangat solid, dan cukup fleksibel untuk diatur dalam banyak konfigurasi untuk membantu Pemulihan Bencana, jika terjadi kesalahan. Kami akan fokus pada skenario seperti yang ditanyakan di atas, cara menyiapkan opsi Pemulihan Bencana kami, dan manfaat dari setiap solusi.
Ketersediaan Tinggi
Dengan replikasi streaming di PostgreSQL , Ketersediaan Tinggi mudah disiapkan dan dipelihara. Tujuannya adalah untuk menyediakan situs failover yang dapat dipromosikan menjadi master jika database utama mati karena alasan apa pun, seperti kegagalan perangkat keras, kegagalan perangkat lunak, atau bahkan pemadaman jaringan. Menghosting replika di host lain memang bagus, tetapi menghostingnya di pusat data lain bahkan lebih baik.
Untuk spesifik menyiapkan replikasi streaming, Somenines memiliki detail mendalam yang tersedia di sini . Dokumentasi Replikasi Streaming PostgreSQL resmi memiliki informasi terperinci tentang protokol replikasi streaming dan cara kerjanya.
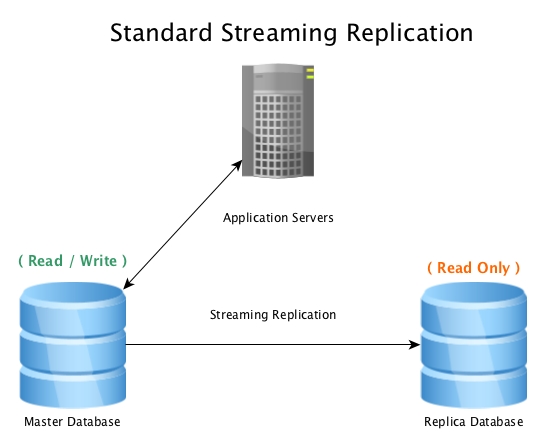
Pengaturan standar akan terlihat seperti ini, database master menerima koneksi baca / tulis, dengan database replika yang menerima semua aktivitas WAL hampir secara real-time, memutar ulang semua aktivitas perubahan data secara lokal.
Ketika database master menjadi tidak dapat digunakan, prosedur failover dimulai untuk membuatnya offline, dan mempromosikan database replika ke master, lalu mengarahkan semua koneksi ke host yang baru dipromosikan. Ini dapat dilakukan dengan mengkonfigurasi ulang penyeimbang beban, konfigurasi aplikasi, alias IP, atau cara cerdas lainnya untuk mengarahkan lalu lintas.
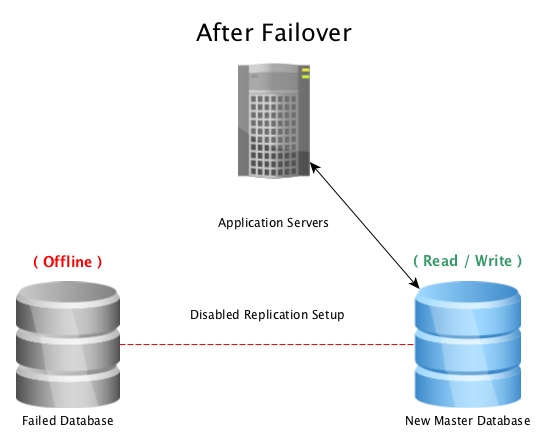
Ketika bencana melanda database master (seperti kegagalan hard drive, pemadaman listrik, atau apa pun yang mencegah master bekerja sebagaimana dimaksud), gagal ke siaga panas adalah cara tercepat untuk tetap online melayani permintaan ke aplikasi atau pelanggan tanpa serius waktu henti. Perlombaan kemudian dilanjutkan untuk memperbaiki host basis data yang gagal, atau membawa replika baru secara online untuk menjaga jaring pengaman agar siaga siap digunakan. Memiliki beberapa standby akan memastikan bahwa jendela setelah kegagalan bencana juga siap untuk kegagalan sekunder, betapapun kecil kemungkinannya.

Catatan: Saat gagal ke replika streaming, replika ini akan melanjutkan di mana master sebelumnya berhenti, jadi ini membantu menjaga database tetap online, tetapi tidak memulihkan data yang hilang secara tidak sengaja.
Pemulihan Titik Dalam Waktu
Pilihan Disaster Recovery lainnya adalah Point in Time Recovery (PITR). Dengan PITR, salinan database dapat dibawa kembali kapan saja kita inginkan, selama kita memiliki cadangan dasar dari sebelum waktu itu, dan semua segmen WAL diperlukan hingga saat itu.
Opsi Pemulihan Point In Time tidak secepat online seperti Hot Standby, namun manfaat utamanya adalah dapat memulihkan snapshot basis data sebelum peristiwa besar seperti tabel yang dihapus, data buruk yang dimasukkan, atau bahkan kerusakan data yang tidak dapat dijelaskan . Apa pun yang akan menghancurkan data sedemikian rupa di mana kita ingin mendapatkan salinannya sebelum penghancuran itu, PITR menyelamatkan hari itu.
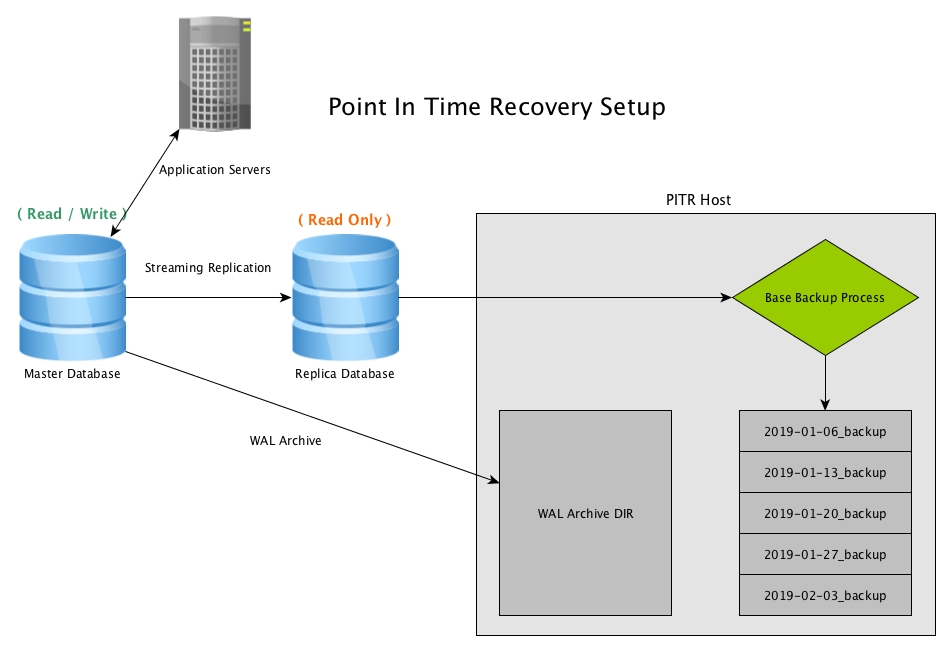
Point in Time Recovery bekerja dengan membuat snapshot database secara berkala, biasanya dengan menggunakan program pg_basebackup, dan menyimpan salinan arsip dari semua file WAL yang dihasilkan oleh master
Pengaturan Pemulihan Titik Dalam Waktu
Pengaturan memerlukan beberapa opsi konfigurasi yang diatur pada master, beberapa di antaranya baik untuk digunakan dengan nilai default pada versi terbaru saat ini, PostgreSQL 11. Dalam contoh ini, kami akan menyalin file 16MB langsung ke host PITR jarak jauh kami menggunakan rsync , dan mengompresinya di sisi lain dengan tugas cron.
Pengarsipan WAL
Menguasai postgresql.conf
1 2 3 | wal_level = replica<font></font>archive_mode = on<font></font>archive_command = 'rsync -av -z %p postgres@pitrseveralnines:/mnt/db/wal_archive/%f' |
CATATAN: Pengaturan archive_command dapat berupa banyak hal, tujuan keseluruhannya adalah mengirim semua file WAL yang diarsipkan ke host lain untuk tujuan keamanan. Jika kita kehilangan file WAL, PITR melewati file WAL yang hilang menjadi tidak mungkin. Biarkan kreativitas pemrograman Anda menjadi gila, tetapi pastikan itu dapat diandalkan.
[Opsional] Kompres file WAL yang diarsipkan:
Setiap pengaturan akan sedikit berbeda, tetapi kecuali database yang bersangkutan sangat ringan dalam pembaruan data, penumpukan file 16MB akan mengisi ruang drive dengan cukup cepat. Skrip kompresi yang mudah, diatur melalui cron, dapat terlihat seperti di bawah ini.
kompres_WAL_archive.sh:
1 2 3 | #!/bin/bash<font></font># Compress any WAL files found that are not yet compressed<font></font>gzip /mnt/db/wal_archive/*[0-F] |
CATATAN: Selama metode pemulihan apa pun, file terkompresi apa pun perlu didekompresi nanti. Beberapa administrator memilih untuk hanya mengompresi file setelah mereka berumur X hari, menjaga ruang keseluruhan tetap rendah, tetapi juga menjaga file WAL yang lebih baru siap untuk pemulihan tanpa kerja ekstra. Pilih opsi terbaik untuk database yang bersangkutan untuk memaksimalkan kecepatan pemulihan Anda.
Cadangan Dasar
Salah satu komponen kunci untuk cadangan PITR adalah cadangan dasar, dan frekuensi pencadangan dasar. Ini bisa per jam, harian, mingguan, bulanan, tetapi memilih opsi terbaik berdasarkan kebutuhan pemulihan serta lalu lintas churn data database. Jika kami memiliki cadangan mingguan setiap hari Minggu, dan kami perlu memulihkan hingga Sabtu sore, maka kami membawa cadangan dasar hari Minggu sebelumnya secara online dengan semua file WAL antara cadangan itu dan Sabtu sore. Jika proses pemulihan ini membutuhkan waktu 10 jam untuk diproses, kemungkinan ini terlalu lama, Pencadangan basis harian akan mengurangi waktu pemulihan itu, karena pencadangan basis akan dimulai dari pagi itu, tetapi juga meningkatkan jumlah pekerjaan pada host untuk pencadangan dasar diri.
Jika pemulihan file WAL selama seminggu hanya membutuhkan beberapa menit, karena basis data melihat churn rendah, maka pencadangan mingguan baik-baik saja. Data yang sama pada akhirnya akan ada, tetapi seberapa cepat Anda dapat mengaksesnya adalah kuncinya.
Dalam contoh kami, kami akan menyiapkan cadangan basis mingguan, dan karena kami menggunakan Replikasi Streaming untuk Ketersediaan Tinggi, serta mengurangi beban pada master, kami akan membuat cadangan dasar dari database replika.
base_backup.sh:
1 2 3 4 5 | #!/bin/bash<font></font>backup_dir="$(date +'%Y-%m-%d')_backup"<font></font>cd /mnt/db/backups<font></font>mkdir $backup_dir<font></font>pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -z |

CATATAN: Perintah pg_basebackup mengasumsikan host ini diatur untuk akses tanpa kata sandi untuk 'replikasi' pengguna pada master, yang dapat dilakukan baik dengan 'percaya' pada pg_hba untuk host cadangan PITR ini, kata sandi dalam file .pgpass, atau lainnya cara-cara yang aman. Perhatikan keamanan saat menyiapkan pencadangan.
Skenario Pemulihan PITR
Menyiapkan Point In Time Recovery hanyalah bagian dari pekerjaan, harus memulihkan data adalah bagian lainnya. Semoga berhasil, ini mungkin tidak akan pernah terjadi, namun sangat disarankan untuk melakukan pemulihan cadangan PITR secara berkala untuk memvalidasi bahwa sistem berfungsi, dan untuk memastikan prosesnya diketahui / ditulis dengan benar.
Dalam skenario pengujian kami, kami akan memilih titik waktu untuk memulihkan dan memulai proses pemulihan. Misalnya: Jumat pagi, pengembang mendorong perubahan kode baru ke produksi tanpa melalui tinjauan kode, dan itu menghancurkan banyak data pelanggan yang penting. Karena Siaga Panas kami selalu sinkron dengan master, gagal melakukannya tidak akan memperbaiki apa pun, karena itu akan menjadi data yang sama. Cadangan PITR adalah yang akan menyelamatkan kita.
Dorongan kode masuk pada jam 11 pagi, jadi kami perlu memulihkan basis data ke tepat sebelum waktu itu, 10:59 kami memutuskan, dan untungnya kami melakukan pencadangan harian sehingga kami memiliki cadangan dari tengah malam pagi ini. Karena kami tidak tahu apa yang dihancurkan, kami juga memutuskan untuk melakukan pemulihan penuh database ini pada host PITR kami, dan membawanya online sebagai master, karena memiliki spesifikasi perangkat keras yang sama dengan master, untuk berjaga-jaga jika ini terjadi. skenario terjadi.
Matikan Master
Karena kami memutuskan untuk memulihkan sepenuhnya dari cadangan dan mempromosikannya ke master, tidak perlu menyimpannya secara online. Kami mematikannya, tetapi menyimpannya untuk berjaga-jaga jika kami perlu mengambil sesuatu darinya nanti, untuk berjaga-jaga.
Siapkan Pencadangan Basis Untuk Pemulihan
Selanjutnya, pada host PITR kami, kami mengambil cadangan basis terbaru kami sebelum acara, yaitu cadangan '2018-12-21_backup'.
1 2 3 4 5 6 7 | mkdir /var/lib/pgsql/11/data<font></font>chmod 700 /var/lib/pgsql/11/data<font></font>cd /var/lib/pgsql/11/data<font></font>tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz<font></font>cd pg_wal<font></font>tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz<font></font>mkdir /mnt/db/wal_archive/pitr_restore/ |
Dengan ini, cadangan dasar, serta file WAL yang disediakan oleh pg_basebackup siap digunakan, jika kita membawanya online sekarang, itu akan pulih ke titik pencadangan terjadi, tetapi kita ingin memulihkan semua transaksi WAL antara tengah malam dan 11:59, jadi kami menyiapkan file recovery.conf kami.
Buat recovery.conf
Karena cadangan ini sebenarnya berasal dari replika streaming, kemungkinan sudah ada file recovery.conf dengan pengaturan replika. Kami akan menimpanya dengan pengaturan baru. Daftar informasi terperinci untuk semua opsi berbeda tersedia di dokumentasi PostgreSQL di sini .
Berhati-hatilah dengan file WAL, perintah pemulihan akan menyalin file terkompresi yang diperlukan ke direktori pemulihan, membuka kompresnya, lalu pindah ke tempat PostgreSQL membutuhkannya untuk pemulihan. File WAL asli akan tetap berada di tempatnya jika diperlukan karena alasan lain.
pemulihan baru.conf:
1 2 | recovery_target_time = '2018-12-21 11:59:00-07'<font></font>restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"' |
Mulai Proses Pemulihan
Sekarang semuanya sudah diatur, kami akan memulai proses pemulihan. Ketika ini terjadi, ada baiknya untuk mengekor log database untuk memastikannya memulihkan sebagaimana dimaksud.

Mulai DBnya:
1 | pg_ctl -D /var/lib/pgsql/11/data start |
Ekor log:
Akan ada banyak entri log yang menunjukkan database pulih dari file arsip, dan pada titik tertentu, itu akan menampilkan baris yang mengatakan "pemulihan berhenti sebelum melakukan transaksi ..."
1 2 3 4 5 | 2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive<font></font>2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive<font></font>2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive<font></font>2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive<font></font>2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07 |
Pada titik ini, proses pemulihan telah menyerap semua file WAL, tetapi juga perlu ditinjau sebelum online sebagai master. Dalam contoh ini, log mencatat bahwa transaksi berikutnya setelah waktu target pemulihan 11:59:00 adalah 11:59:01, dan tidak dipulihkan. Untuk Verifikasi, masuk ke database dan lihat, database yang sedang berjalan harus berupa snapshot pada 11:59 tepat.
Ketika semuanya terlihat baik, saatnya untuk mempromosikan pemulihan sebagai master.
1 2 3 4 5 | postgres=# SELECT pg_wal_replay_resume();<font></font> pg_wal_replay_resume<font></font>----------------------<font></font><font></font>(1 row) |
Sekarang, database sedang online, pulih ke titik yang kami putuskan, dan menerima koneksi baca / tulis sebagai node master. Pastikan semua parameter konfigurasi sudah benar dan siap untuk produksi.
Basis data sedang online, tetapi proses pemulihan belum selesai! Sekarang cadangan PITR ini online sebagai master, standby baru dan pengaturan PITR harus diatur, sampai master baru ini mungkin online dan melayani aplikasi, tetapi tidak aman dari bencana lain sampai semuanya diatur kembali.
Skenario Pemulihan Titik Dalam Waktu Lainnya
Membawa kembali cadangan PITR untuk seluruh database adalah kasus ekstrem, tetapi ada skenario lain di mana hanya sebagian data yang hilang, rusak, atau buruk. Dalam kasus ini, kita bisa berkreasi dengan opsi pemulihan kita. Tanpa membuat master offline dan menggantinya dengan cadangan, kami dapat membawa cadangan PITR online ke waktu yang kami inginkan di host lain (atau port lain jika ruang tidak menjadi masalah), dan mengekspor data yang dipulihkan dari cadangan secara langsung ke dalam database induk. Ini dapat digunakan untuk memulihkan beberapa baris, beberapa tabel, atau konfigurasi data apa pun yang diperlukan.
Dengan replikasi streaming dan Pemulihan Point In Time, PostgreSQL memberi kami fleksibilitas tinggi untuk memastikan kami dapat memulihkan data apa pun yang kami butuhkan, selama kami memiliki host siaga yang siap digunakan sebagai master, atau cadangan siap untuk dipulihkan. Opsi Pemulihan Bencana yang baik dapat diperluas lebih lanjut dengan opsi cadangan lainnya, lebih banyak node replika, beberapa situs cadangan di berbagai pusat data dan benua, pg_dumps berkala pada replika lain, dll.
Opsi-opsi ini dapat bertambah, tetapi pertanyaan sebenarnya adalah 'seberapa berharga data tersebut, dan berapa banyak yang bersedia Anda keluarkan untuk mendapatkannya kembali?'. Banyak kasus hilangnya data adalah akhir dari bisnis, jadi opsi Pemulihan Bencana yang baik harus ada untuk mencegah hal terburuk terjadi
==================================
PostgreSQL Replication for Disaster Recovery
With Disaster Recovery, we aim to set up systems to handle anything that could go wrong with our database. What happens if the database crashes? What if a developer accidently truncates a table? What if we find out some data was deleted last week but we didn’t notice it until today? These things happen, and having a solid plan and system in place will make the DBA look like a hero when everyone else’s hearts have already stopped when a disaster rears its ugly head.
Any database that has any sort of value should have a way to implement one or more Disaster Recovery options. PostgreSQL has a very solid replication system built in, and is flexible enough to be set up in many configurations to aid with Disaster Recovery, should anything go wrong. We’ll focus on scenarios like questioned above, how to set up our Disaster Recovery options, and the benefits of each solution.
High Availability
With streaming replication in PostgreSQL, High Availability is simple to set up and maintain. The goal is to provide a failover site that can be promoted to master if the main database goes down for any reason, such as hardware failure, software failure, or even network outage. Hosting a replica on another host is great, but hosting it in another data center is even better.
For specifics for setting up streaming replication, Severalnines has a detailed deep dive available here. The official PostgreSQL Streaming Replication Documentation has detailed information on the streaming replication protocol and how it all works.
A standard setup will look like this, a master database accepting read / write connections, with a replica database receiving all WAL activity in near real-time, replaying all data change activity locally.
When the master database becomes unusable, a failover procedure is initiated to bring it offline, and promote the replica database to master, then pointing all connections to the newly promoted host. This can be done by either reconfiguring a load balancer, application configuration, IP aliases, or other clever ways to redirect the traffic.
When disaster hits a master database (such as a hard drive failure, power outage, or anything that prevents the master from working as intended) , failing over to a hot standby is the quickest way to stay online serving queries to applications or customers without serious downtime. The race is then on to either fix the failed database host, or bring a new replica online to maintain the safety net of having a standby ready to go. Having multiple standbys will ensure that the window after a disastrous failure is also ready for a secondary failure, however unlikely it may seem.
Note: When failing over to a streaming replica, it will pick up where the previous master left off, so this helps with keeping the database online, but not recovering accidentally lost data.
Point In Time Recovery
Another Disaster Recovery option is Point in TIme Recovery (PITR). With PITR, a copy of the database can be brought back at any point in time we want, so long as we have a base backup from before that time, and all WAL segments needed up till that time.
A Point In Time Recovery option isn’t as quickly brought online as a Hot Standby, however the main benefit is being able to recover a database snapshot before a big event such as a deleted table, bad data being inserted, or even unexplainable data corruption. Anything that would destroy data in such a way where we would want to get a copy before that destruction, PITR saves the day.
Point in Time Recovery works by creating periodic snapshots of the database, usually by use of the program pg_basebackup, and keeping archived copies of all WAL files generated by the master
Point In Time Recovery Setup
Setup requires a few configuration options set on the master, some of which are good to go with default values on the current latest version, PostgreSQL 11. In this example, we’ll be copying the 16MB file directly to our remote PITR host using rsync, and compressing them on the other side with a cron job.
WAL Archiving
Master postgresql.conf
1 2 3 | wal_level = replicaarchive_mode = onarchive_command = 'rsync -av -z %p postgres@pitrseveralnines:/mnt/db/wal_archive/%f' |
NOTE: The setting archive_command can be many things, the overall goal is to send all archived WAL files away to another host for safety purposes. If we lose any WAL files, PITR past the lost WAL file becomes impossible. Let your programming creativity go crazy, but make sure it’s reliable.
[Optional] Compress the archived WAL files:
Every setup will vary somewhat, but unless the database in question is very light in data updates, the buildup of 16MB files will fill up drive space fairly quickly. An easy compression script, set up through cron, could look like below.
compress_WAL_archive.sh:
1 2 3 | #!/bin/bash# Compress any WAL files found that are not yet compressedgzip /mnt/db/wal_archive/*[0-F] |
NOTE: During any recovery method, any compressed files will need to be decompressed later. Some administrators opt to only compress files after they are X number of days old, keeping overall space low, but also keeping more recent WAL files ready for recovery without extra work. Choose the best option for the databases in question to maximize your recovery speed.
Base Backups
One of the key components to a PITR backup is the base backup, and the frequency of base backups. These can be hourly, daily, weekly, monthly, but chose the best option based on recovery needs as well as the traffic of the database data churn. If we have weekly backups every Sunday, and we need to recover all the way to Saturday afternoon, then we bring the previous Sunday’s base backup online with all the WAL files between that backup and Saturday afternoon. If this recovery process takes 10 hours to process, this is likely undesirably too long, Daily base backups will reduce that recovery time, since the base backup would be from that morning, but also increase the amount of work on the host for the base backup itself.

If a week long recovery of WAL files takes just a few minutes, because the database sees low churn, then weekly backups are fine. The same data will exist in the end, but how fast you’re able to access it is the key.
In our example, we’ll set up a weekly base backup, and since we are using Streaming Replication for High Availability, as well as reducing the load on the master, we’ll be creating the base backup off of the replica database.
base_backup.sh:
1 2 3 4 5 | #!/bin/bashbackup_dir="$(date +'%Y-%m-%d')_backup"cd /mnt/db/backupsmkdir $backup_dirpg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -z |
NOTE: The pg_basebackup command assumes this host is set up for passwordless access for user ‘replication’ on the master, which can be done either by ‘trust’ in pg_hba for this PITR backup host, password in the .pgpass file, or other more secure ways. Keep security in mind when setting up backups.
PITR Recovery Scenario
Setting up Point In Time Recovery is only part of the job, having to recover data is the other part. With good luck, this may never have to happen, however it’s highly suggested to periodically do a restoration of a PITR backup to validate that the system does work, and to make sure the process is known / scripted correctly.
In our test scenario, we’ll choose a point in time to recover to and initiate the recovery process. For example: Friday morning, a developer pushes a new code change to production without going through a code review, and it destroys a bunch of important customer data. Since our Hot Standby is always in sync with the master, failing over to it wouldn’t fix anything, as it would be the same data. PITR backups is what will save us.
The code push went in at 11 AM, so we need to restore the database to just before that time, 10:59 AM we decide, and luckily we do daily backups so we have a backup from midnight this morning. Since we don’t know what all was destroyed, we also decide to do a full restore of this database on our PITR host, and bring it online as the master, as it has the same hardware specifications as the master, just in case this scenario happened.
Shutdown The Master
Since we decided to restore fully from a backup and promote it to master, there’s no need to keep this online. We shut it down, but keep it around in case we need to grab anything from it later, just in case.
Set Up Base Backup For Recovery
Next, on our PITR host, we fetch our most recent base backup from before the event, which is backup ‘2018-12-21_backup’.
1 2 3 4 5 6 7 | mkdir /var/lib/pgsql/11/datachmod 700 /var/lib/pgsql/11/datacd /var/lib/pgsql/11/datatar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gzcd pg_waltar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gzmkdir /mnt/db/wal_archive/pitr_restore/ |
With this, the base backup, as well as the WAL files provided by pg_basebackup are ready to go, if we bring it online now, it will recover to the point the backup took place, but we want to recover all of the WAL transactions between midnight and 11:59 AM, so we set up our recovery.conf file.
Create recovery.conf
Since this backup actually came from a streaming replica, there is likely already a recovery.conf file with replica settings. We will overwrite it with new settings. A detailed information list for all different options are available on PostgreSQL’s documentation here.

Being careful with the WAL files, the restore command will copy the compressed files it needs to the restore directory, uncompress them, then move to where PostgreSQL needs them for recovery. The original WAL files will remain where they are in case needed for any other reasons.
New recovery.conf:
1 2 | recovery_target_time = '2018-12-21 11:59:00-07'restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"' |
Start The Recovery Process
Now that everything is set up, we will start the process for recovery. When this happens, it’s a good idea to tail the database log to make sure it’s restoring as intended.
Start the DB:
1 | pg_ctl -D /var/lib/pgsql/11/data start |
Tail the logs:
There will be many log entries showing the database is recovering from archive files, and at a certain point, it will show a line saying “recovery stopping before commit of transaction …”
1 2 3 4 5 | 2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07 |
At this point, the recovery process has ingested all WAL files, but is also in need of review before it comes online as a master. In this example, the log notes that the next transaction after the recovery target time of 11:59:00 was 11:59:01, and it was not recovered. To Verify, log in to the database and take a look, the running database should be a snapshot as of 11:59 exactly.
When everything looks good, time to promote the recovery as a master.
1 2 3 4 5 | postgres=# SELECT pg_wal_replay_resume(); pg_wal_replay_resume----------------------(1 row) |
Now, the database is online, recovered to the point we decided, and accepting read / write connections as a master node. Ensure all configuration parameters are correct and ready for production.
The database is online, but the recovery process is not done yet! Now that this PITR backup is online as the master, a new standby and PITR setup should be set up, until then this new master may be online and serving applications, but it’s not safe from another disaster until that’s all set up again.
Other Point In Time Recovery Scenarios
Bringing back a PITR backup for a whole database is an extreme case, but there are other scenarios where only a subset of data is missing, corrupt, or bad. In these cases, we can get creative with our recovery options. Without bringing the master offline and replacing it with a backup, we can bring a PITR backup online to the exact time we want on another host (or another port if space isn’t an issue), and export the recovered data from the backup directly into the master database. This could be used to recover a handful of rows, a handful of tables, or any configuration of data needed.
With streaming replication and Point In Time Recovery, PostgreSQL gives us great flexibility on making sure we can recover any data we need, as long as we have standby hosts ready to go as a master, or backups ready to recover. A good Disaster Recovery option can be further expanded with other backup options, more replica nodes, multiple backup sites across different data centers and continents, periodic pg_dumps on another replica, etc.
These options can add up, but the real question is ‘how valuable is the data, and how much are you willing to spend to get it back?’. Many cases the loss of the data is the end of a business, so good Disaster Recovery options should be in place to prevent the worst from happening.
Tidak ada komentar:
Posting Komentar